
Pangram Uzayında Görme
Pangram 3.3.2’nin içsel temsillerinin incelenmesi
Yazan: Elyas Masrour, Katherine Thai ve Bradley Emi
Haziran 2026
Giriş
ChatGPT’nin 2022’deki piyasaya sürülmesinden bu yana, yapay zeka destekli yazma şaşırtıcı bir hızla yaygınlaştı. Artık okuduğumuz metinlerin büyük bir kısmında yapay zeka tarafından üretilen metinlere rastladığımızdan, bazı yazı türlerinin bir makine tarafından üretildiğinde değerini yitirdiği açıkça ortaya çıkmıştır. Akademi dünyasında, makalelerin amacı öğrencilerin muhakeme becerilerini geliştirmektir. Ticari alanda ise ürün yorumları, diğer insanların deneyimlerini yansıttığı için değerlidir.
Pangram, bu soruna yönelik en gelişmiş yapay zeka algılama modelleri geliştiren bir araştırma şirketidir. Amiral gemisi ürünümüz, sektörde en düşük yanlış pozitif oranlarına sahip, çok dilli özellikler sunan ve yapay zeka tarafından üretilen içerik ile yapay zeka desteğiyle oluşturulan içerik arasında ayrım yapabilen bir yapay zeka metin algılama modelidir.
2024 yılında ilk teknik raporumuzu yayınladığımızdan bu yana, yapay zeka alanındaki gelişmelerin dalga dalga yayılmasını izlemek için eşsiz bir konumda bulunduk. Araştırmacılarımız aşırı katı içerik filtreleriyle mücadele ettiler ve mod çöküşü sorunuyla da yeterince karşılaştılar, ve uzun tirelerin dalgalarından ve “delve” kelimesinden kaçındı.
Amiral gemisi modelimiz, bu dizi sınıflandırma görevine göre ince ayarlanmış bir LLM’dir. Perplexity veya burstiness gibi özel ölçütler kullanmıyoruz. Herhangi bir manuel özellik çıkarma işlemi de yapmıyoruz. AI Phrases adında, kullanıcılarımıza yapay zeka metinlerinde daha sık görülen ifadeler hakkında bilgi sunduğumuz, müşterilere yönelik bir ürünümüz var. Ancak bunlar, model için doğrudan özellik olarak kullanılmıyor. Bir süre sonra insan merak ediyor: Model ne görüyor?
Araştırmacılar olarak bu soru bizim için önemlidir. Kestirme yollara başvurmayı önlemek, modelin istenmeyen davranışlarını düzeltmek ve bu sorunu derinlemesine anlamak konusunda son derece motiveyiz. Bu yazıda, belge düzeyinde analiz kullanarak yaptığımız ilk yorumlanabilirlik çalışmalarımızı özetleyeceğiz.
Veriler
Üretim eğitim kümesinden alınan, alan içi ayrılmış örneklerden bir yorumlanabilirlik veri kümesi oluşturduk. Bu sayfadaki etkileşimli gezgin, insan ve yapay zeka arasında eşit olarak bölünmüş, 20 çift sayılı katmana yayılmış dengeli bir 5.000 belgeden oluşan alt kümeyi kullanır. Yapay zeka örnekleri, sınıflandırıcı testi için kullanılan altı model ailesi genelinde aşağıdaki model varyantlarını kapsamaktadır.
Modeller
- Claude 3.7 Sonnet
- Claude Sonnet 4
- Claude Sonnet 4.5
- Claude Opus 4
- Claude Opus 4.1
- Claude Opus 4.5
- GPT-3.5 Turbo (Kasım ’23)
- GPT-3.5 Turbo (Ocak ’24)
- GPT-4 (Mart 2023)
- GPT-4 (Haziran ’23)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- Qwen 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
Kaynak etki alanları
- Haberler
- Bilimsel Özetler
- Ürün Yorumları
- İşletme Yorumları
- Reddit Yaratıcı Yazım
- Reddit ELI5
- Kitaplar (Kendi Yayınladıklarım)
- Kitaplar (Project Gutenberg)
- Vikipedi (İngilizce)
- Vikipedi (Çokdilli)
- Lang-8 (İngilizce İkinci Dil Olarak)
Pangram 3.3.2 Genel Bakış
Pangram 3.3.2, Pangram Labs tarafından 2026 yılında piyasaya sürülen bir yapay zeka algılama modelidir. Pangram 3.3 ile aynı temel modeli kullanır; ancak performansı artıran sonradan yapılan hata düzeltmeleri içerir. Pangram 3.3, Pangram 3.2’nin yerini almış ve yeni nesil büyük dil modellerinin (LLM) çıktılarında, insan tarafından yazılmış metinlerde ve yapay zeka tarafından üretilen uzun metinlerde geri çağırma oranını artırırken, ana dili İngilizce olmayan metinlerdeki yanlış pozitif sonuçları azaltmıştır.
Model kartıPangram 3.3 model kartını okuyunPangram 3.3.2 sürümünün ayrıntılarına göz atın.Makaleyi okuYorumlanabilirlik çalışmalarımız devam etmektedir. Bu makale boyunca, yöntemlerimizi geriye dönük olarak Pangram 3.2 ve Pangram 3.1’e de uyguluyoruz.
Yöntemler
Etkinleştirme işlemleri
EditLens mimarisi, tek bir yapıya indirgenen kova tabanlı bir sınıflandırma sistemidir ai_yardım_puanı. Bu projede, modelin nihai çıktısını bir kenara bırakarak, bunun yerine modelin öğrendiği iç temsillere odaklanıyoruz. Bunları incelemek için, belirli bir girdi belgesiyle modelin ileri geçişini gerçekleştirip, modelin çeşitli iç katmanlarındaki gizli temsillerini kaydederek aktivasyonları topluyoruz. Bu projede, ağdaki her çift numaralı katman için her belgeye ait aktivasyonları çıkardık.
Boyut Azaltma
Çıkarılan her bir aktivasyon vektörü 5.120 boyutluydu. Temsilleri daha iyi anlayabilmek için bir dizi boyut azaltma tekniği kullandık.
PCA
Temel Bileşen Analizi (PCA), en basit doğrusal izdüşüm yöntemidir: aktivasyon uzayında varyansın en yüksek olduğu yönleri belirler. Bu projede, ağın sonuna doğru varyansın büyük kısmının 1. ve 2. temel bileşenlerde yer aldığını tespit ettik ve bu nedenle bunları birbirlerine göre grafiğe döktük.
UMAP
UMAP, komşuluk yapısını korumak üzere tasarlanmış doğrusal olmayan bir görünüm sunar. Modelin iç uzayında iki belge birbirine yakınsa, UMAP bunları 2B uzayda da yakın tutmaya çalışır. Ancak, kümeler arasındaki eksenler ve mesafeler aşırı yorumlanmamalıdır.
t-SNE
t-SNE, yerel kümeleri ortaya çıkarmada etkili olan bir başka doğrusal olmayan projeksiyon yöntemidir. Bu projenin amaçları doğrultusunda, t-SNE’yi kullanarak, model aileleri veya insan/yapay zeka etiketleri gibi anlamsal açıdan önemli grupların, ağ derinleştikçe gözle görülür şekilde kümelenip kümelenmediğini inceliyoruz.
Doğrusal Problar
Boyut azaltma yöntemlerimizden elde ettiğimiz nitel sonuçları nicel olarak değerlendirmek için doğrusal sondalar kullanıyoruz. Her katman için, basit bir sınıflandırıcının o katmanın aktivasyon vektörlerinden hedef etiketi geri kazanıp kazanamayacağını inceliyoruz. Sondanın doğruluğunun yüksek olması, ilgili ayrımın temsil uzayının doğrusal olarak erişilebilir bir yönünde zaten kodlanmış olduğu anlamına gelir.
Yapay Zeka Algılama Görevi
İkili Doğruluk
Ağın genelinde nihai sınıf ayrımının nasıl gerçekleştirildiğini anlamak için, her katmanda doğrusal problar eğitiyoruz. İnsan ve yapay zeka arasında eşit olarak bölünmüş 500 örnek üzerinde, 80:20 eğitim/test dağılımı ile eğitim yapıyoruz. Ağın henüz başlarında bile performansın zaten yüksek olduğunu görüyoruz: 2. katmandan hemen sonra 0,83 doğruluk oranına ulaşıyoruz. Bu, sezgilerimizle örtüşüyor; zira “kelime torbası” modelleri, yapay zeka algılama görevi için genellikle kullanışlı temel modeller olarak kabul edilir. Ağ boyunca doğruluk oranı artarak 24. katmanda 1,0’a ulaşıyor.
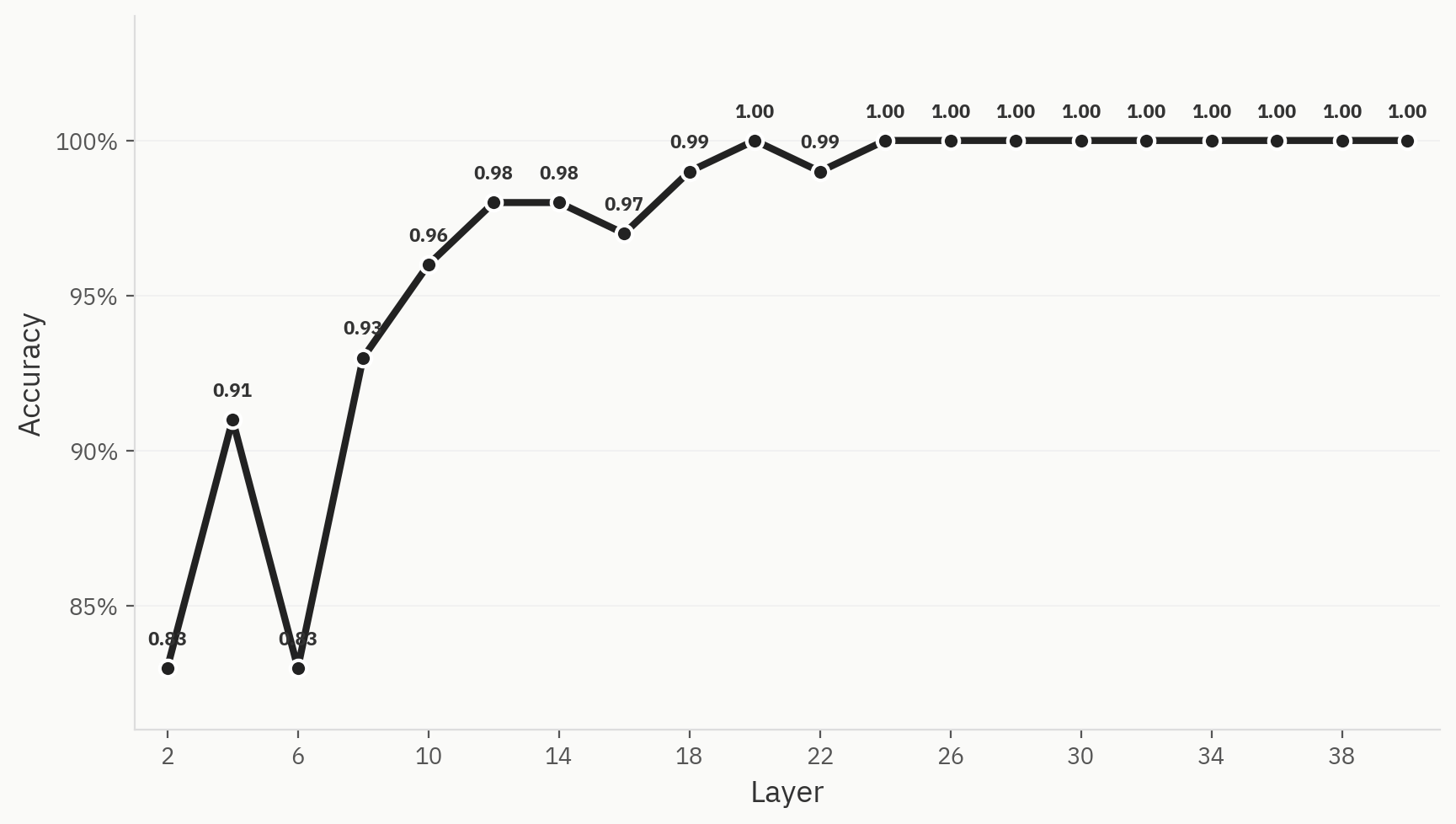
Şekil 3: Bu ayrım, üç boyut azaltma yönteminin hepsinde açıkça görülmektedir.
LLM Sınıflandırması
t-SNE ve UMAP grafiklerinde, belgelerin kendilerini oluşturan modele göre kümeleniyor gibi göründüğünü fark ettik. Bu bizim için sürpriz oldu. Pangram’ın eski sürümlerinde ayrı bir LLM sınıflandırıcı başlığı vardı, ancak bu görev uzun zamandır kaldırılmıştı. Pangram 3.3.2’nin eğitim sürecinde, bir AI belgesinin kaynak modeline karşılık gelen hiçbir etiket verilmemektedir.
Buna rağmen, kaynak model ailesinin etrafında kümeler oluştu. Daha da ilginç olanı ise, bu kümelerin ağın tüm katmanlarında ortaya çıkıyor gibi görünmesidir.
Model Kümelerinin Ortaya Çıkışı
Model ailesine göre aynı gömülü değerleri renklendirin; böylece katmanlar arasında sağlayıcı düzeyindeki geometriyi görebilirsiniz.
Şekil 4: Model ailesine göre renklendirilmiş Katman 2-40 gömüleri. Sağlayıcı düzeyindeki kümeler, sonraki katmanlarda daha belirgin hale gelmektedir.
Sonda
Bu olguyu nicel olarak değerlendirmek için, altı model ailesi (Anthropic, OpenAI, Google, Qwen, Llama, DeepSeek) üzerinde, her model ailesi için 500 örnek ve toplamda 3.000 örnek kullanarak, 80:20 eğitim/test dağılımı ile bir sınıflandırıcı eğittik. Sadece Pangram aktivasyonlarını kullanarak belirli bir belgenin kaynak model ailesini sınıflandırabilen bir sonda eğitebildiğimizi ve bunun maksimum top-1 doğruluğunun %91 olduğunu tespit ettik.
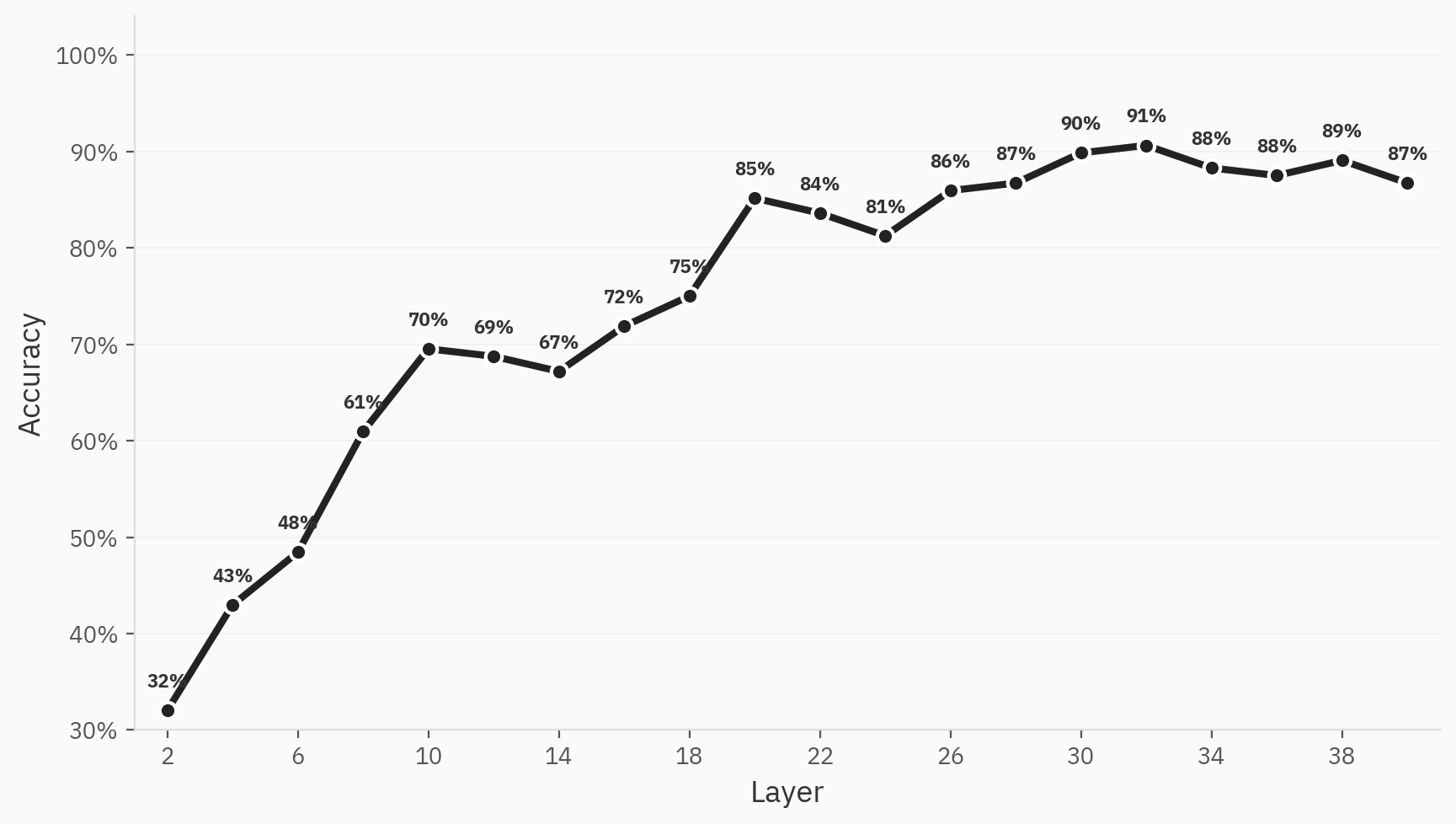
Ortaya Çıkması Garanti Edilmez
İlk yorumlanabilirlik deneylerimiz, çeşitli modeller üzerinde yapılan testleri içeriyordu. Bizi şaşırtan bir şekilde, “LLM sınıflandırma” yeteneğinin ortaya çıkması, bu projede modeller arasında önemli ölçüde farklılık gösteren tek bulgudan biriydi.
Aşağıdaki şekil, Pangram 3.1, 3.2 ve 3.3.2 modellerinin kümeleme davranışlarını karşılaştırmaktadır. Model, kurum içi son değerlendirmelerimizde ikili insan-yapay zeka görevinde 3.1 modelinden daha iyi performans göstermiş olsa da, Pangram 3.2’de model kümeleri genel olarak Pangram 3.1 veya 3.3.2’ye kıyasla daha az belirgindir.
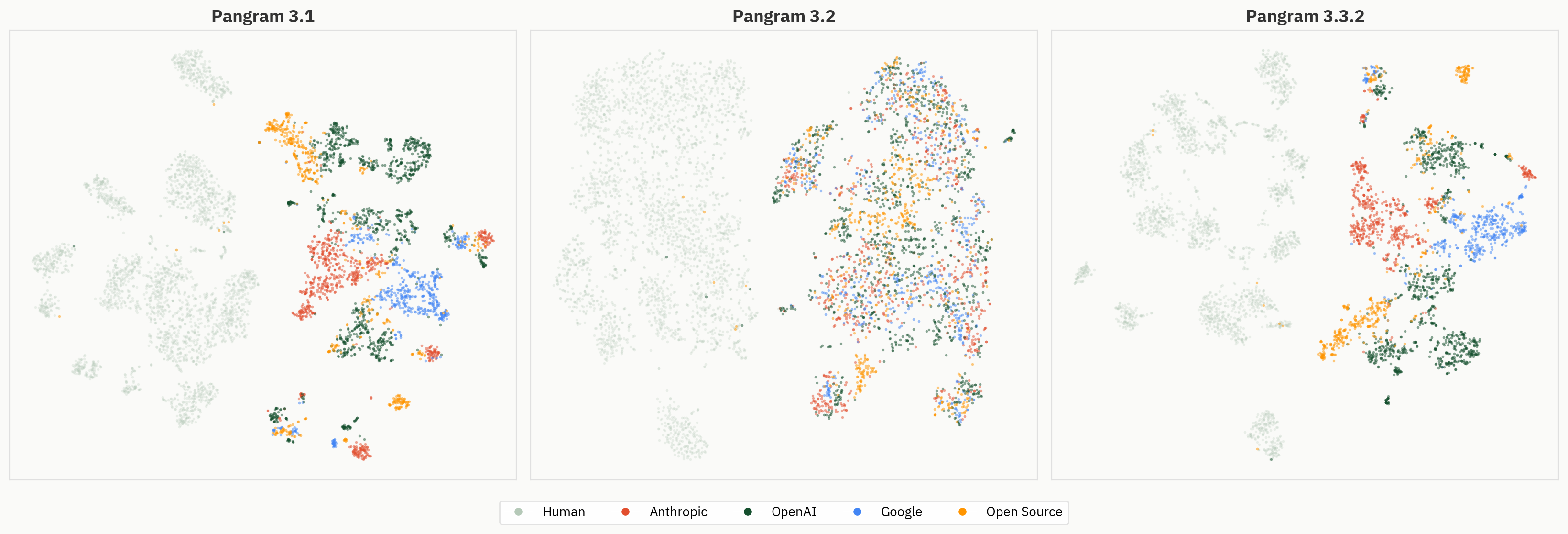
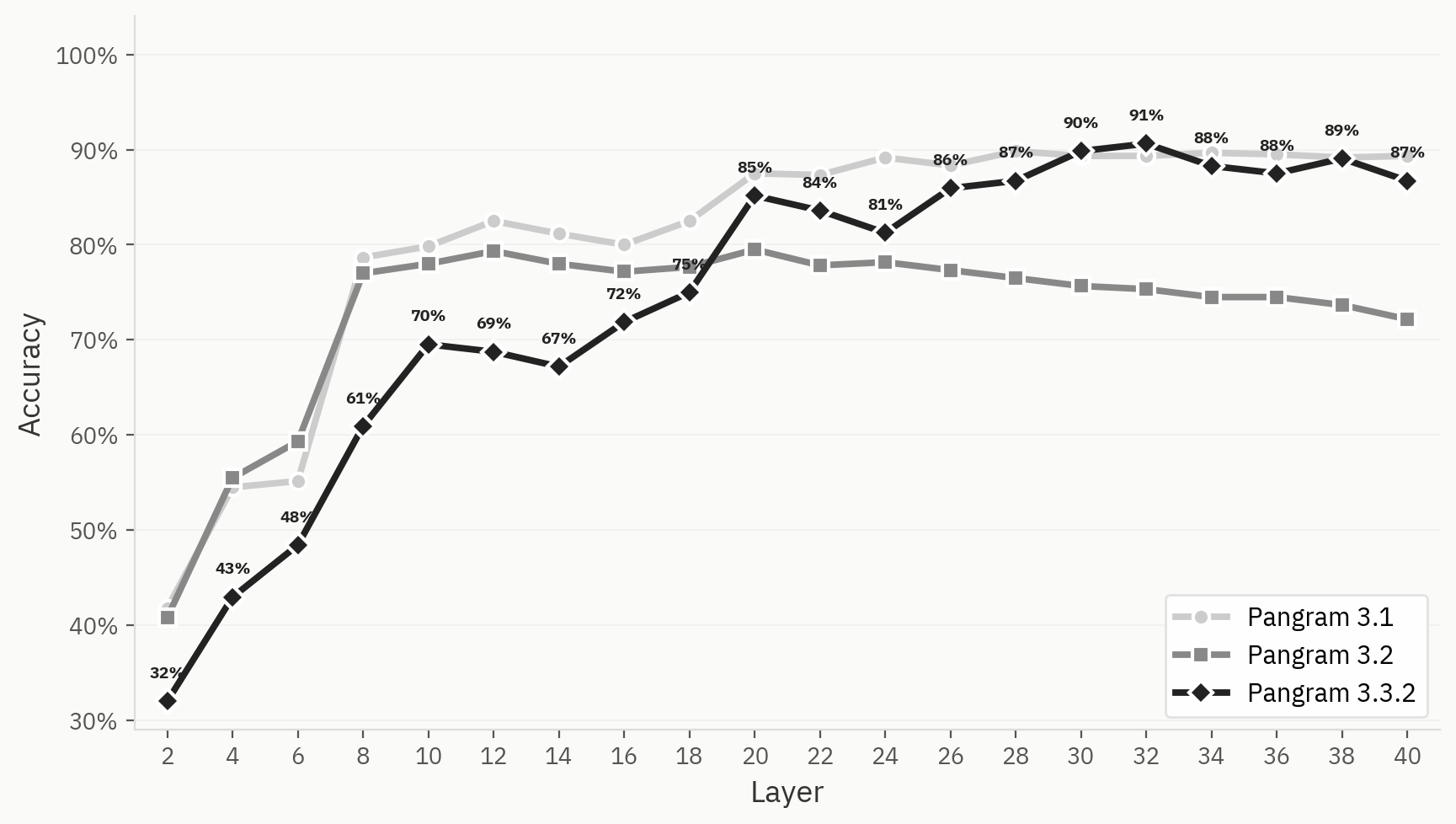
Bu farkı daha net bir şekilde ortaya koymak için, LLM sınıflandırıcı probunu Pangram 3.1, 3.2 ve 3.3.2 üzerinde karşılaştırıyoruz. Üçü de ilk katmanlarda top-1 doğruluk oranlarını artırıyor; ancak Pangram 3.2 için prob, 12. katmandan sonra düşmeye başlarken, Pangram 3.1 ve 3.3.2’de yüksek seviyede kalıyor.
İnsancı
“Humanizer’lar”, yapay zeka tarafından üretilen metinleri, yapay zeka algılayıcılarından kaçacak şekilde değiştirmek üzere tasarlanmış bir tür karşıt araç sınıfıdır. İnsancıllaştırılmış metnin, aktivasyon uzayında insan ve yapay zeka metinlerine göre nerede konumlandığını görmek için, yaklaşık 1.900 örnekten oluşan ayrı bir “insancıllaştırıcılar” veri kümesi oluşturduk. Bu veri kümesi, üç üretici model (Claude Sonnet 4.5, Gemini 2.5 Pro ve GPT-5), on farklı insancıllaştırıcı hizmet ve orijinal yorumlanabilirlik veri kümesiyle aynı kaynak alanları arasında kabaca dengelenmiştir. Saldırı riskleri nedeniyle, hangi hizmetleri kullandığımızı açıklamıyoruz.
Model, “Humanizers”ı Nasıl Okur?
Humanizer veri setimizdeki bazı örnekler, modelimiz için gerçekten de tespit edilmesi zor örneklerdir. Burada, orijinal eğitim düzeninde olduğu gibi, insanlaştırılmış metinlerin “AI” olarak etiketlendiği durum hariç, insan/AI görevi için aynı doğrusal probu kullanıyoruz. Gördüğümüz kadarıyla, ilk katmandan itibaren bile insanlaştırılmış metinler, doğrudan AI karşılığına kıyasla tutarlı bir şekilde daha insanca olarak algılanmaktadır.
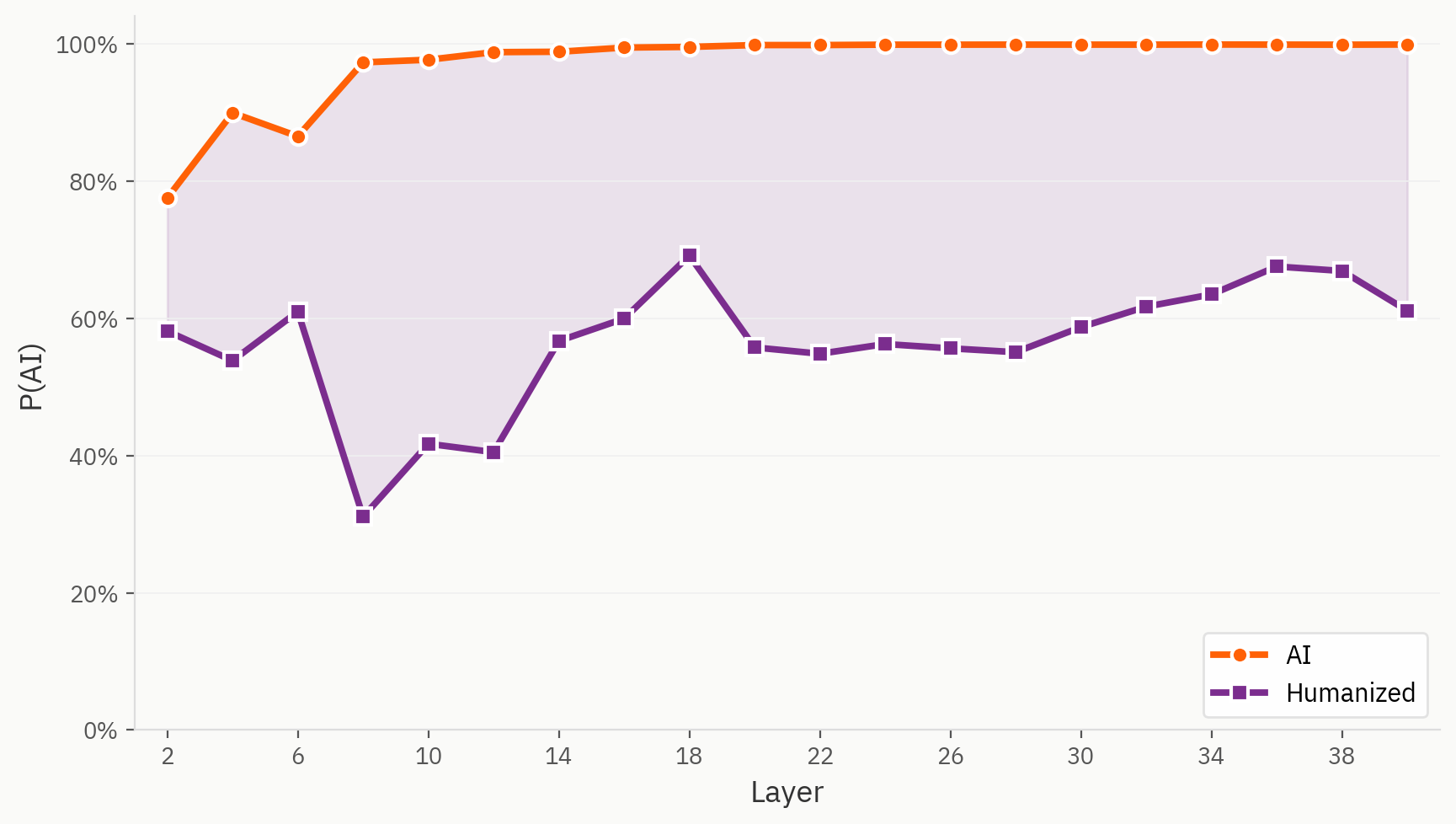
Gömme Uzayında İnsanlaştırıcıların Bulunduğu Yerler
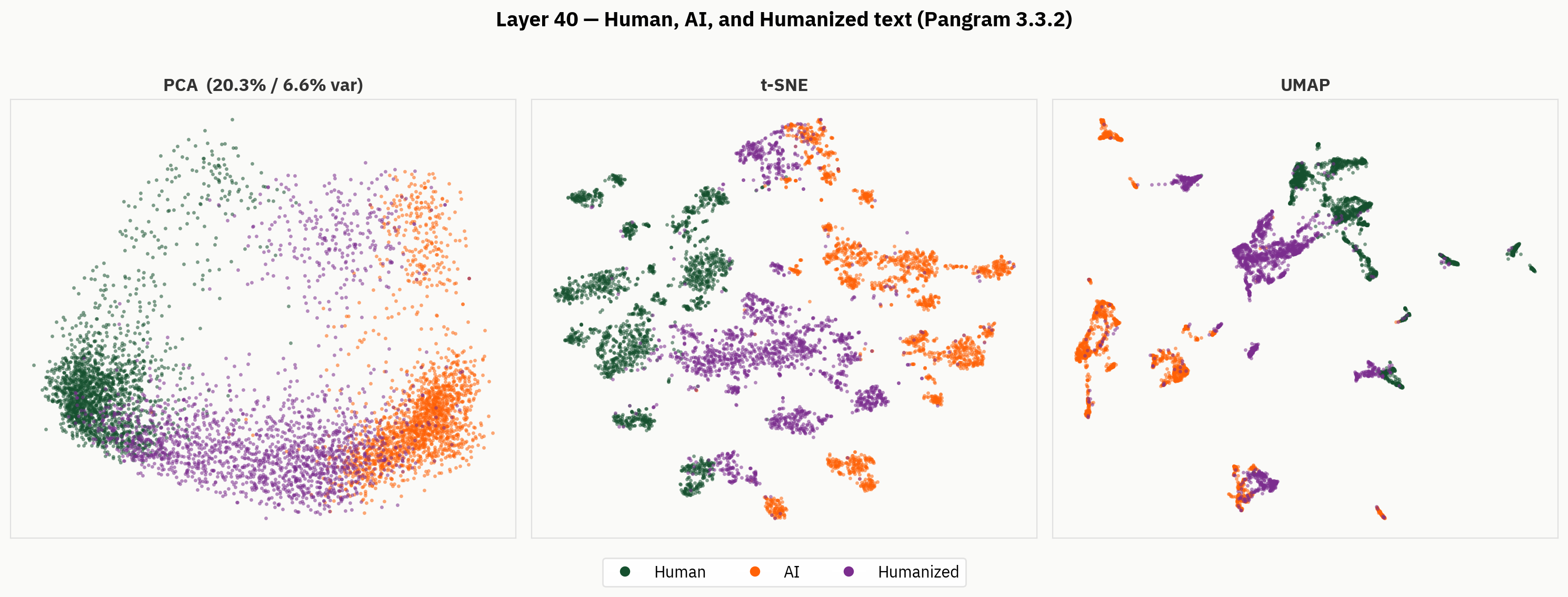
Ancak, nihai çıktıların ötesine baktığımızda, insanlaştırılmış metinlerin çok daha zengin bir temsilini görüyoruz. Aşağıda, boyut azaltma yöntemlerimizi insan, yapay zeka ve insanlaştırılmış metinlere uyguluyoruz. Niteliksel olarak, insanlaştırıcıların aktivasyon uzayında ayrı bölümleri işgal etme eğiliminde olduklarını ve insan ile yapay zeka bölgelerinin dışında kümeler oluşturduklarını gözlemleyebiliyoruz.
Hipotezimiz, insan tarafından yazılmış metinler için etiketler olmamasına rağmen, modelin insan tarafından yazılmış, insan ve yapay zeka tarafından üretilmiş metinleri birbirinden ayırt edebilmesidir. Ancak, nihai sonuçta model bu sinyali birleştirmeye zorlanmaktadır ve bunu tutarsız bir şekilde yapmaktadır.
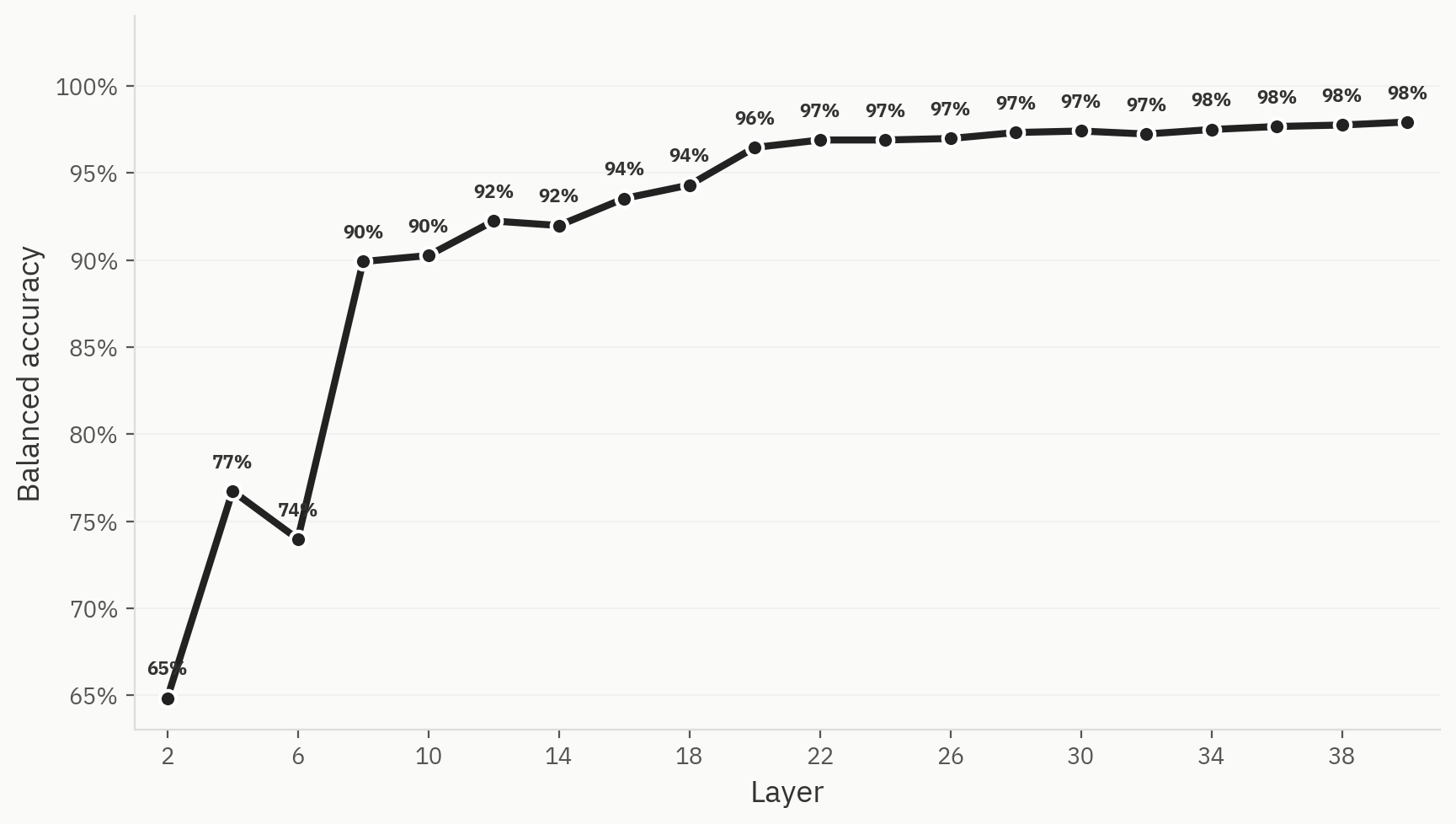
Sonda
Bu hipotezi doğrulamak için, yapay zeka, insan ve insanlaştırılmış metin etiketlerini içeren üç yönlü bir doğrusal prob eğittik. Prob, ağın erken aşamalarında yüksek bir top-1 doğruluk oranına ulaştı ve sonunda %98 seviyesinde sabitlendi.
Sonuç
Buradaki çalışmamız, Pangram’ın iç temsillerinin, yalnızca nihai ikili çıktıdan anlaşıldığından daha fazla yapı içerdiğini ortaya koymaktadır. Katmanlar arasında, insan ve yapay zeka tarafından üretilen belgelerin birbirinden ayrıldığını, model ailesine ait bilgilerin ortaya çıktığını ve insan tarafından yazılmış metinlerin aktivasyon uzayında kendine özgü bir bölgeyi işgal ettiğini gözlemliyoruz. Bu bulgular henüz başlangıç aşamasındadır, ancak modelin her şeyi tek bir algılama puanına indirgemeden önce ne öğrendiğini anlamamız için bize yararlı bir yol haritası sunmaktadır.
Bu yazı, yorumlanabilirlik konusundaki çabalarımızın yalnızca ilk adımlarını göstermektedir; ancak kurum içinde bu araştırma yönüne büyük bir heyecan ve ilgi duyuyoruz.
Pangram modelleriyle ilgili yorumlanabilirlik ve açıklanabilirlik konusundaki vizyonumuz, bu modellerin aşağıdakileri yapabilmesidir:
- Model davranışına ilişkin kurum içinde daha iyi bir anlayış sağlamak.
- Her bir Pangram sonucu için destekleyici kanıtlar ve daha net açıklamalar sunun.
Yorumlanabilirlik, yapay zeka tespit araştırmaları veya bu çalışmadaki diğer konularla ilgilenen bir araştırmacıysanız, lütfen elyas@pangram.com adresinden bizimle iletişime geçin.
