Makine öğrenimi ve veri ekipleri için yapay zeka tabanlı algılama
Makine öğrenimi mühendisleri ve veri bilimcileri için yapay zeka algılayıcısı
LLM eğitimini ve veri seçimini optimize edin. Ön eğitim veya ince ayar veri kümelerinizdeki sentetik metinleri %99,98 doğruluk oranı ve yüksek verimli API performansı ile filtreleyerek model çökmesini önleyin.
Google, Tesla ve Stanford'dan araştırmacılar tarafından geliştirilmiştir. ICLR ve Maryland Üniversitesi tarafından doğrulanmıştır.
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")'ın Küresel Markaları Tarafından Güvenilen

















Kullanım örnekleri
Modellerinizi
adresinde hatalı verilerle eğitmeyin.
Sentetik metinler, kamuya açık veri kümelerini kirletiyor. Metin külliyatının saflığını korumak için, en doğru AI algılama motorunu kullanarak eğitim süreçlerinizden AI tarafından üretilen içeriği filtreleyin.
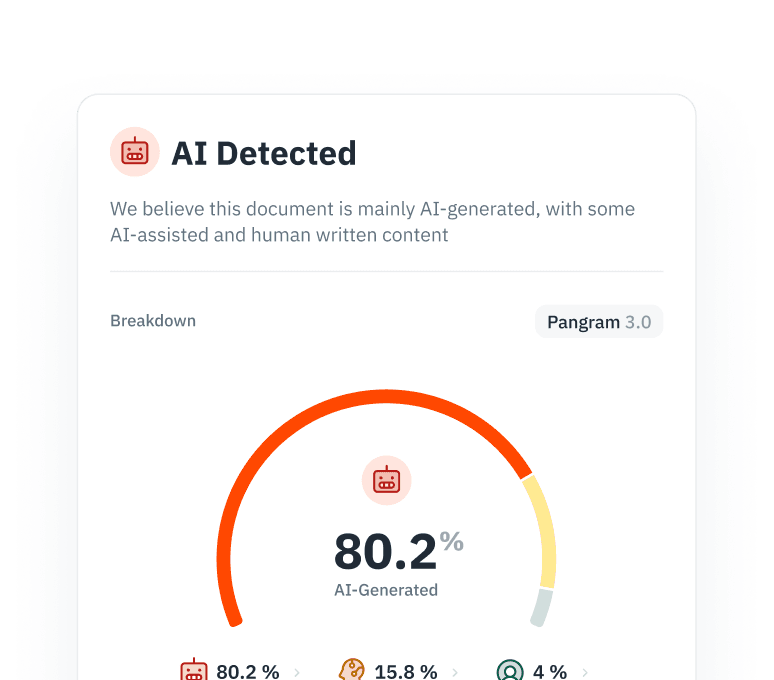
Model Çökmesini Önle
AI tarafından üretilen içerik üzerinde tekrarlayan eğitim, model performansını ve çeşitliliği düşürür. Veri toplama süreçlerinizden AI tarafından yazılmış içeriği tespit edip filtreleyerek veri kümesinin saflığını koruyun.
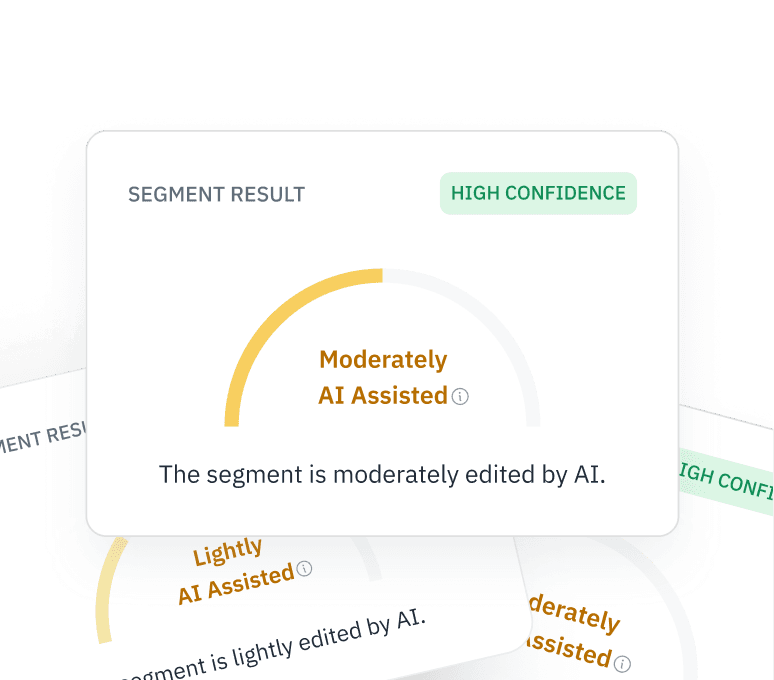
RLHF Girişlerini Doğrula
İnsan Geri Bildirimi (RLHF) verilerinizin gerçekten insan kaynaklı olduğundan emin olun. Crowd-worker'ların ince ayar görevleriniz için yanıtlar oluşturmak üzere ChatGPT'yi kullanıp kullanmadığını tespit edin.
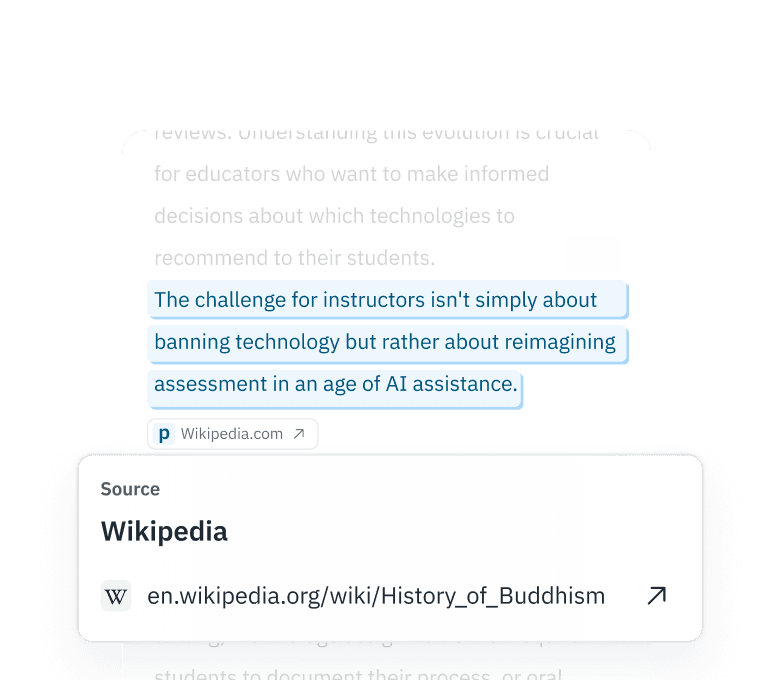
Ayrıntılı Yorumlanabilirlik
İkili bir etiketle yetinmeyin. Premium API'miz, token düzeyinde olasılıklar sunar; böylece tamamen sentetik "gürültüyü" eleyerek, insan tarafından düzenlenmiş segmentleri koruyabilirsiniz.
Teknik yaklaşım
adresinden güvenebileceğiniz bir model
Veri filtreleme konusunda güvenilirliğe ihtiyaç duyan mühendisler için tasarlanmıştır. Modelimiz, yanlış pozitif sonuçları, saldırılara karşı dayanıklılığı ve sürekli gelişen yapay zeka çıktılarını ele almaktadır.

Sert Negatif Madencilik
Yanlış pozitif sonuçları en aza indirmek ve değerli insan verilerinin silinmemesini sağlamak için, stil açısından resmi veya tekrarlayıcı nitelikteki insan yazıları olan "kesin negatifler" üzerinde eğitim yapıyoruz.
Karşıt Ortam Dayanıklılığı
Pangram, yeniden ifade edilmiş veya değiştirilmiş yapay zeka içeriklerini işler. Modellerimiz, gizlenmiş sentetik metinleri tespit etmek üzere "insanlaştırıcılar" ve saldırgan saldırılara karşı eğitilmiştir.
Geleceğe Hazırlık
GPT-5, Claude 3.5 ve Llama 3 gibi en yeni modellerden gelen metinleri algılar ve filtrelerinizin mevcut en iyi performans düzeyinin (SOTA) her zaman bir adım önünde olmasını sağlar.
Entegrasyon
veri akışınız için tasarlandı

01
Python SDK
pangram-sdk'yı yükleyin ve sadece birkaç satır kodla algılama işlevini Airflow veya Databricks boru hatlarınıza entegre edin. Bağlantı havuzu ve hata yönetimi için optimize edilmiştir.
Belgeleri Görüntüle →
02
Yüksek Verimli
API'si
Büyük veri kümelerini düşük gecikme süresiyle işleyin. Altyapımız toplu işlemeyi destekler ve verimliliği garanti eder; kurumsal veri toplama işlemleri için milyonlarca isteği işleyebilir.
API Anahtarını Al →
03
Güvenlik ve
'e Uyum
SOC 2 Tip 2 sertifikasına tam olarak sahibiz. Özel uç noktalar ve sıkı veri saklama politikaları sunuyoruz — hiçbir zaman sizin özel verilerinizi eğitim amaçlı kullanmıyoruz.
Daha Fazla Bilgi →
Sık Sorulan Sorular
Yapay Zeka Algılama SSS
Makine öğrenimi mühendisleri
ve veri bilimcileri için yapay zeka algılama konusunda sık sorulan sorular.
Evet. Pangram-sdk'yı yükleyerek, sadece birkaç satır kodla Airflow veya Databricks iş akışlarına algılama özelliğini entegre edebilirsiniz. API'mız, yüksek verimli kurumsal veri toplama işlemleri için optimize edilmiştir ve düşük gecikme süresiyle milyonlarca isteği destekler.
Daha fazlasını keşfedin
'da yapay zeka tabanlı algılama: her kuruluş için
Geliştiriciler İçin
Geliştiriciler ve mühendislik ekipleri için yapay zeka kod algılama. ChatGPT, Copilot ve Claude tarafından oluşturulan yapay zeka kodlarını Python, Java, C++ ve diğer dillerde tespit edin.
Daha fazla bilgi edinin →İçerik Denetimi İçin
Güven ve güvenlik ekipleri için yapay zeka destekli içerik denetimi. API aracılığıyla yapay zeka tarafından oluşturulan yorumları, sahte yorumları ve sentetik içeriği geniş ölçekte tespit edin.
Daha fazla bilgi edinin →Üniversiteler için
Üniversiteler ve yükseköğretim kurumları için yapay zeka tabanlı tespit. Öğrenci ödevlerini doğrulayın, araştırma makalelerini inceleyin ve kurumun itibarını koruyun.
Daha fazla bilgi edinin →Eğitim verilerinizi bugün temizleyin
Model çökmesini önleyin, RLHF girdilerini doğrulayın ve veri kümelerinizdeki sentetik içeriği %99,98 doğrulukla filtreleyin.
adresinden güncellemelerimize abone olun
