
パングラム空間での視覚
パングラム 3.3.2 の内部表現の考察
執筆:エリアス・マスル、キャサリン・タイ、ブラッドリー・エミ
2026年6月
はじめに
2022年にChatGPTが登場して以来、AIを活用した文章作成は驚異的なスピードで広がっています。現在、私たちが読むものの多くにAI生成のテキストが散見されるようになったため、機械によって作成された場合、ある種の文章はその価値を失ってしまうことが明らかになってきました。学術分野において、エッセイは学生の論理的思考力を養うことを目的としています。市場においては、製品レビューは他者の体験を反映しているからこそ価値があるのです。
Pangramは、この課題に対処するための最先端のAI検出モデルを開発する研究企業です。当社の主力製品は、業界トップクラスの低い誤検知率、多言語対応機能、そしてAI生成とAI支援の区別機能を備えたAIテキスト検出モデルです。
2024年に最初のホワイトペーパーを発表して以来、私たちはAIの進歩が次々と押し寄せる様子を、他にはない視点から観察してきました。当社の研究者たちは、過度に厳格なコンテンツフィルターとの格闘を重ね、モード崩壊も数多く目にしてきました、そして、次々と押し寄せる長ダッシュや「delve」という単語をかわした。
当社の主力モデルは、このシーケンス分類タスク向けに微調整されたLLMです。パープレキシティやバースト性といった独自の評価指標は使用していません。また、手動による特徴量抽出も行っていません。当社には「AI Phrases」という顧客向け製品があり、AI生成テキストに頻繁に登場するフレーズに関する情報をユーザーに提供しています。しかし、これらはモデルの特徴量として直接使用されることはありません。しばらくすると、どうしても気になってしまいます。「モデルは一体何を見ているのだろうか?」と。
研究者である私たちにとって、この問いは重要です。私たちは、近道を防ぎ、意図しないモデルの挙動を修正し、この問題を深く理解することに強い意欲を持っています。本記事では、文書レベルの分析を用いた、解釈可能性に関する私たちの初期の取り組みの概要を説明します。
データ
我々は、本番用トレーニングセットから抽出したドメイン内のテスト用サンプルを用いて、解釈可能性データセットを構築しました。このページのインタラクティブエクスプローラーでは、人間とAIのサンプルが均等に分割された、バランスが取れた5,000ドキュメントのサブセットを使用しており、これは20の偶数番号のレイヤーに均等に分割されています。AIサンプルは、分類器プローブに使用された6つのモデルファミリーにまたがり、以下のモデルバリエーションを網羅しています。
モデル
- Claude 3.7 ソネット
- クロード・ソネット 第4番
- クロード・ソネット 4.5
- クロード・オパス4
- クロード 作品4.1
- クロード・オパス 4.5
- GPT-3.5 Turbo(2023年11月)
- GPT-3.5 Turbo(2024年1月)
- GPT-4(2023年3月)
- GPT-4(2023年6月)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- Gemini 2.5 Flash
- Gemini 2.5 Pro
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- クウェン 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
ソースドメイン
- ニュース
- 科学抄録
- 商品レビュー
- ビジネスレビュー
- Redditの創作執筆
- Reddit ELI5
- 書籍(自費出版)
- 書籍(プロジェクト・グーテンベルク)
- ウィキペディア(英語版)
- ウィキペディア(多言語版)
- Lang-8 (ESL)
Pangram 3.3.2 概要
Pangram 3.3.2 は、2026年に Pangram Labs がリリースした AI 検出モデルです。Pangram 3.3 と同じ基盤モデルを採用しており、その後のバグ修正によりパフォーマンスが向上しています。Pangram 3.3 は Pangram 3.2 の後継モデルであり、新しい LLM の出力、人間らしいテキスト、AI 生成の長文コンテンツにおけるリコール率を向上させると同時に、非ネイティブ英語による文章での誤検知率を低減しました。
モデルカードパングラム 3.3 モデルカードを読むPangram 3.3.2 のリリース詳細をご覧ください。記事を読む解釈可能性に関する研究は現在も進行中です。また、本記事では、Pangram 3.2 および Pangram 3.1 に対しても、我々の手法を遡及的に適用しています。
方法
アクティベーション
EditLensのアーキテクチャは、バケットベースの分類システムであり、単一の ai_assistance_score. 本プロジェクトでは、モデルの最終的な出力結果は無視し、代わりにモデルが学習する内部表現に焦点を当てます。これらを調査するために、特定の入力文書に対してモデルのフォワードパスを実行し、複数の内部層におけるモデルの隠れ表現を保存することで、活性化値を収集します。本プロジェクトでは、ネットワーク全体の偶数番号の層について、すべての文書に対する活性化値を抽出しました。
次元削減
抽出された各活性化ベクトルは5,120次元であった。表現をより深く理解するために、我々はいくつかの次元削減手法を採用した。
PCA
主成分分析(PCA)は最も単純な線形射影であり、活性化空間において分散が最大となる方向を特定するものです。本プロジェクトでは、ネットワークの終端付近において、分散の大部分が主成分1および2に含まれていることが判明したため、これらを互いにプロットしました。
UMAP
UMAPは、近傍構造を保持するように設計された非線形な視点を提示します。モデルの内部空間において2つの文書が近接している場合、UMAPは2次元空間においてもそれらを近接させたままにしようとします。ただし、軸の位置やクラスター間の距離については、過度に解釈すべきではありません。
t-SNE
t-SNEもまた、局所的なクラスターを明らかにするのに適した非線形投影法の一つです。本プロジェクトの目的上、t-SNEを用いて、モデルファミリーや「人間/AI」といったラベルなど、意味的に重要なグループが、ネットワークが深くなるにつれて視覚的にクラスター化されるかどうかを検証します。
リニアプローブ
我々は、次元削減手法から得られる定性的な結果を定量化するために、線形プローブを用いる。各層について、単純な分類器がその層の活性化ベクトルからターゲットラベルを復元できるかどうかを検証する。プローブの精度が高いということは、関連する区別が、表現空間の線形にアクセス可能な方向にすでにエンコードされていることを意味する。
AI検出タスク
二進法の精度
ネットワークの各層において、最終的なクラス分類がどのように達成されるかを理解するため、各層で線形プローブを学習させます。人間とAIのサンプルを均等に分割した500個のサンプルを用いて、学習データとテストデータの割合を80:20として学習を行います。 その結果、ネットワークの初期段階であっても、すでに高い性能が確認されました。具体的には、第2層の直後で0.83の精度を達成しています。これは、「バッグ・オブ・ワード」モデルがAI検出タスクにおいてしばしば有用なベースラインとなるという我々の直感と一致しています。ネットワーク全体を通じて精度は向上し続け、第24層で1.0に達して頭打ちとなりました。
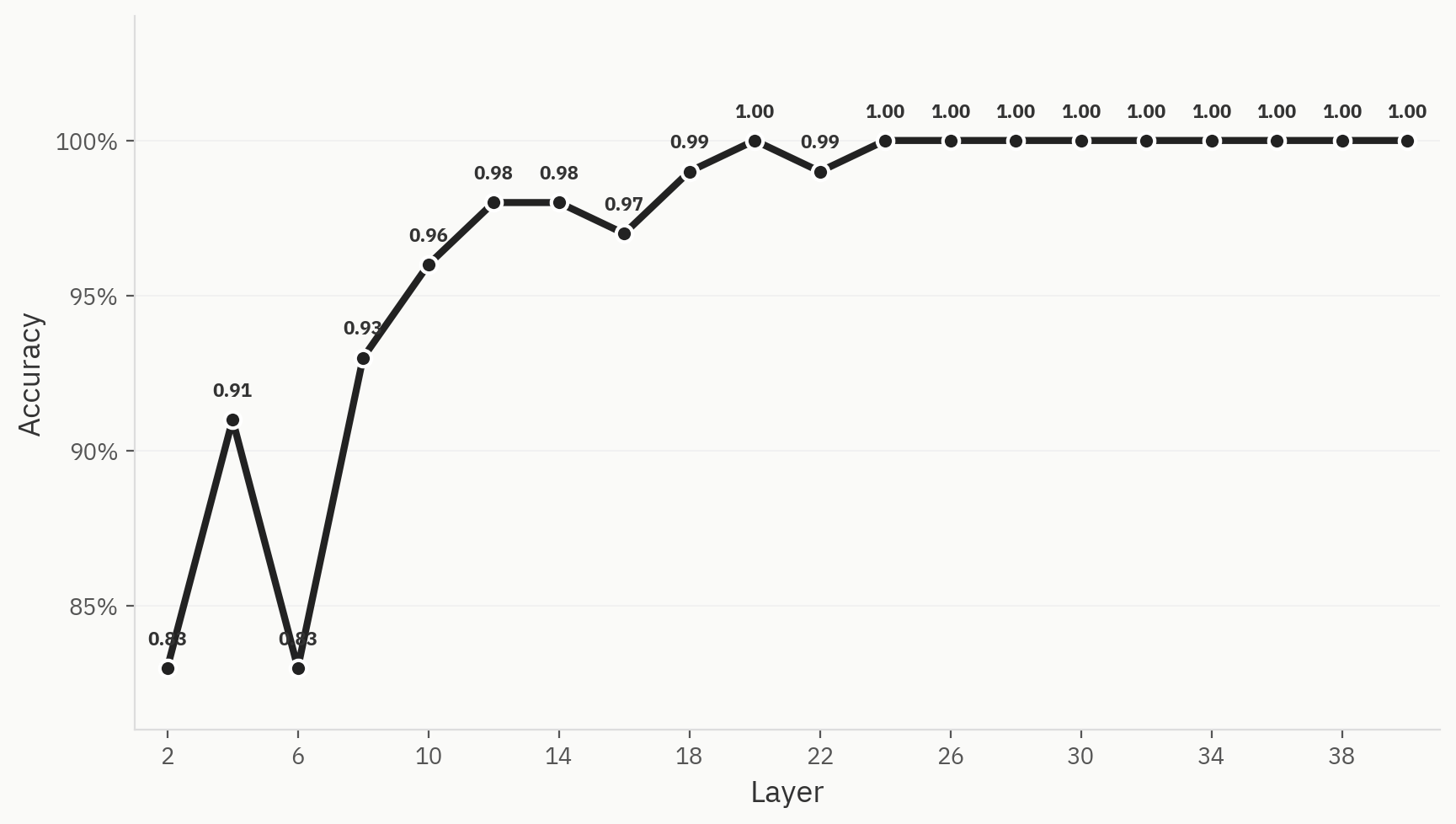
図3この分離は、3つの次元削減手法のすべてにおいてはっきりと確認できる。
LLMの分類
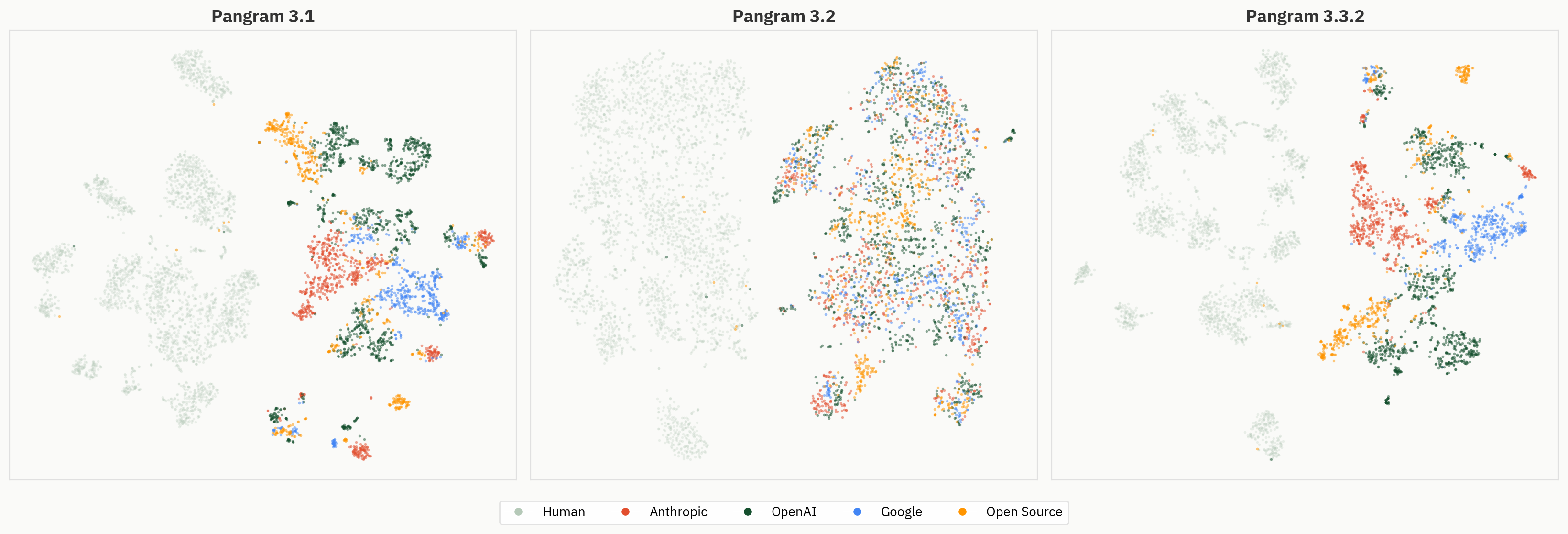
t-SNEおよびUMAPのプロットを見ると、ドキュメントが、それらを生成したモデルごとにクラスタリングされているように見受けられました。これは私たちにとって意外な発見でした。Pangramの以前のバージョンには、LLM分類器用の独立したヘッドがありましたが、その特定のタスクはとっくに廃止されていました。Pangram 3.3.2の学習プロセスでは、AIドキュメントの生成元モデルに対応するラベルは一切与えられていません。
それでも、元のモデルファミリーを中心にクラスターが形成されました。さらに興味深いことに、これらのクラスターはネットワークの各層全体にわたり出現しているようです。
モデルクラスターの形成
モデルファミリーごとに同じ埋め込みに色を付けると、レイヤー全体にわたってプロバイダーレベルの幾何学的構造が浮かび上がってきます。
図4モデルファミリーごとに色分けされたレイヤー2~40の埋め込み。後方のレイヤーになるにつれて、プロバイダーレベルのクラスターがより鮮明に見えるようになる。
プローブ
この現象を定量化するため、6つのモデルファミリー(Anthropic、OpenAI、Google、Qwen、Llama、DeepSeek)について、各モデルファミリーあたり500サンプル、合計3,000サンプルを用いて、訓練データとテストデータの比率を80:20として分類器を学習させた。 その結果、パングラム活性化値のみを用いて、特定のドキュメントの元のモデルファミリーを分類できるプローブを実際に学習させることができ、最大トップ1精度は91%に達することが判明した。
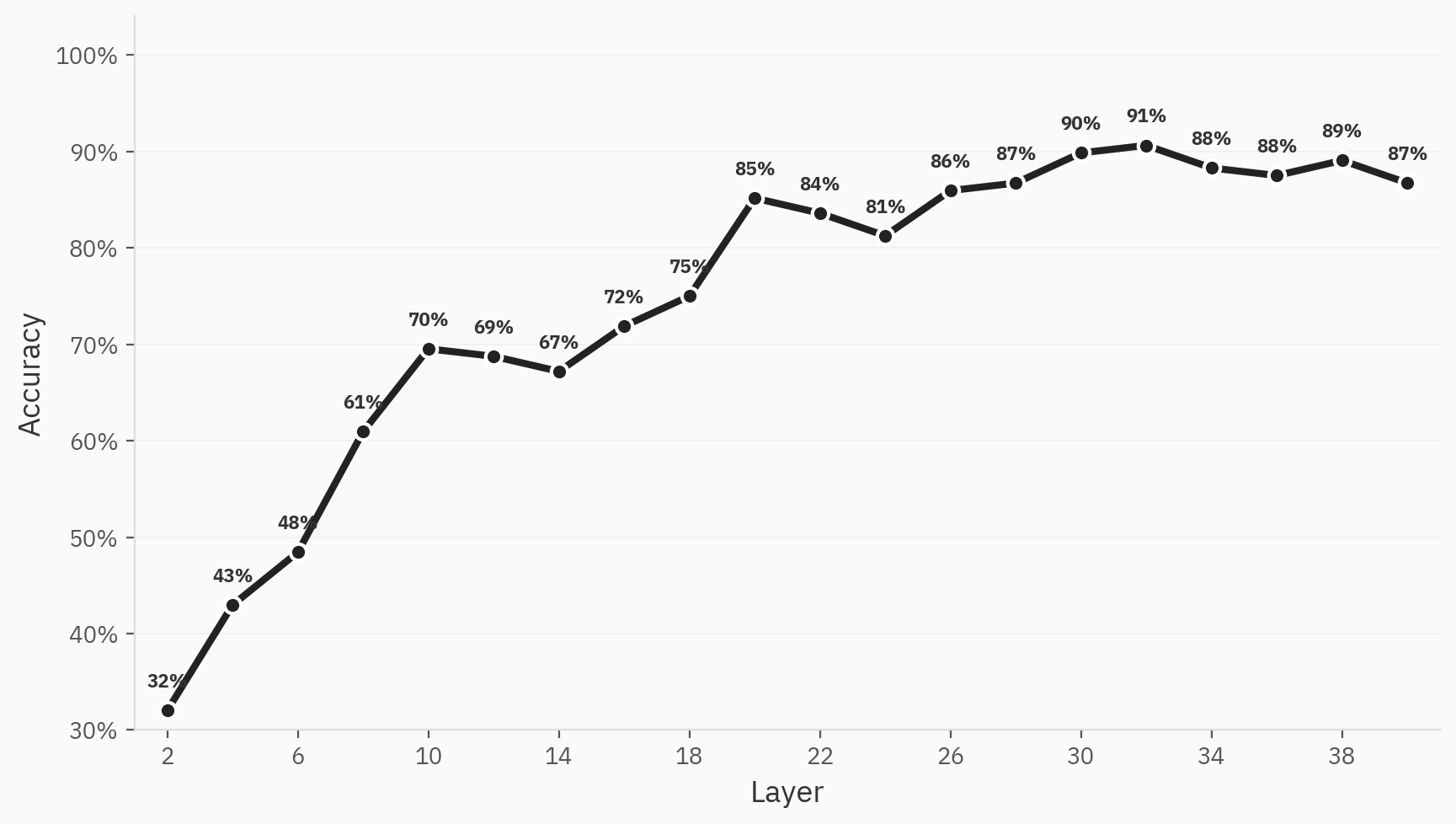
出現が保証されるわけではない
初期の解釈可能性に関する実験では、複数のモデルを用いた検証を行いました。意外なことに、「LLM分類」能力の出現は、このプロジェクトにおいてモデル間で実質的な違いが見られた数少ない知見の一つでした。
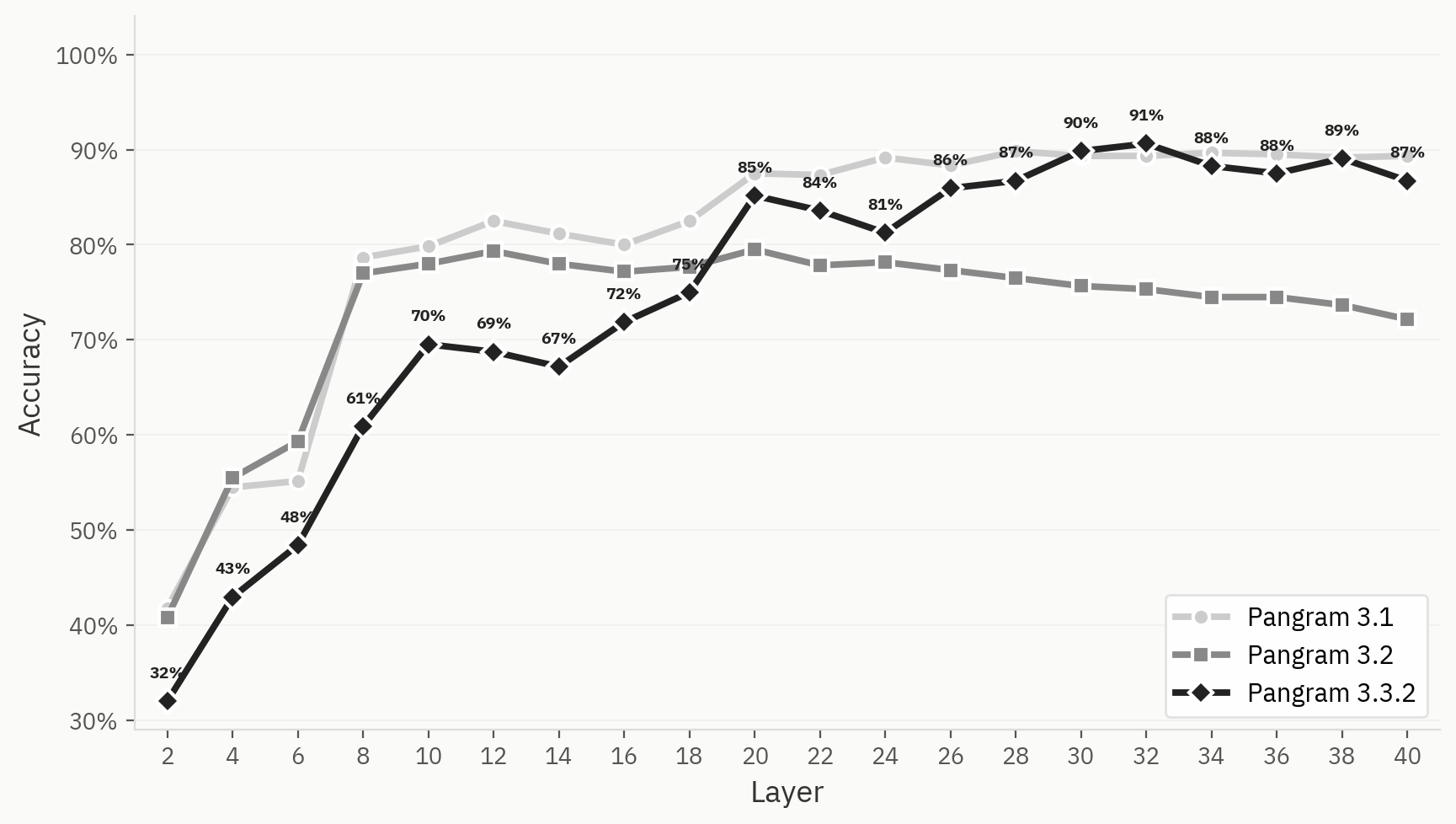
下の図は、Pangram 3.1、3.2、および3.3.2のクラスタリング挙動を比較したものです。当社の内部サインオフ評価において、このモデルは二値の「人間対AI」タスクで3.1よりも優れた性能を示しましたが、Pangram 3.2では、Pangram 3.1や3.3.2に比べて、モデルのクラスタリングが全体的に明確ではありません。
この違いをさらに明確にするため、Pangram 3.1、3.2、および3.3.2におけるLLM分類器のプローブを比較する。3つとも初期の層ではトップ1精度が向上しているが、Pangram 3.2のプローブは12層目以降で低下し始めるのに対し、Pangram 3.1と3.3.2は高い水準を維持している。
ヒューマナイザー
「ヒューマナイザー」とは、AI検出ツールを回避するようにAI生成テキストを改変することを目的とした、敵対的ツールの1種である。 ヒューマナイズされたテキストが、活性化空間において人間のテキストやAIのテキストとどのような位置関係にあるかを確認するため、別途「ヒューマナイザー」データセットを作成しました。このデータセットは約1,900件のサンプルで構成されており、3つの生成モデル(Claude Sonnet 4.5、Gemini 2.5 Pro、GPT-5)、10種類の異なるヒューマナイザーサービス、および元の解釈可能性データセットと同じソースドメイン間で、おおむねバランスが取れています。 敵対的リスクを考慮し、使用したサービスの名称については開示しません。
モデルが「ヒューマナイザー」をどのように読み取るか
ヒューマナイザーデータセットに含まれる一部のサンプルは、確かに当モデルにとって検出が困難です。ここでは、元の学習設定と同様に、ヒューマナイズされたテキストをAIとしてラベル付けすることを除き、人間/AIタスクに対して同じ線形プローブを使用しています。その結果、最初の層からすでに、ヒューマナイズされたテキストは、それに対応するAIテキストよりも一貫して「人間らしい」と判定されていることがわかります。
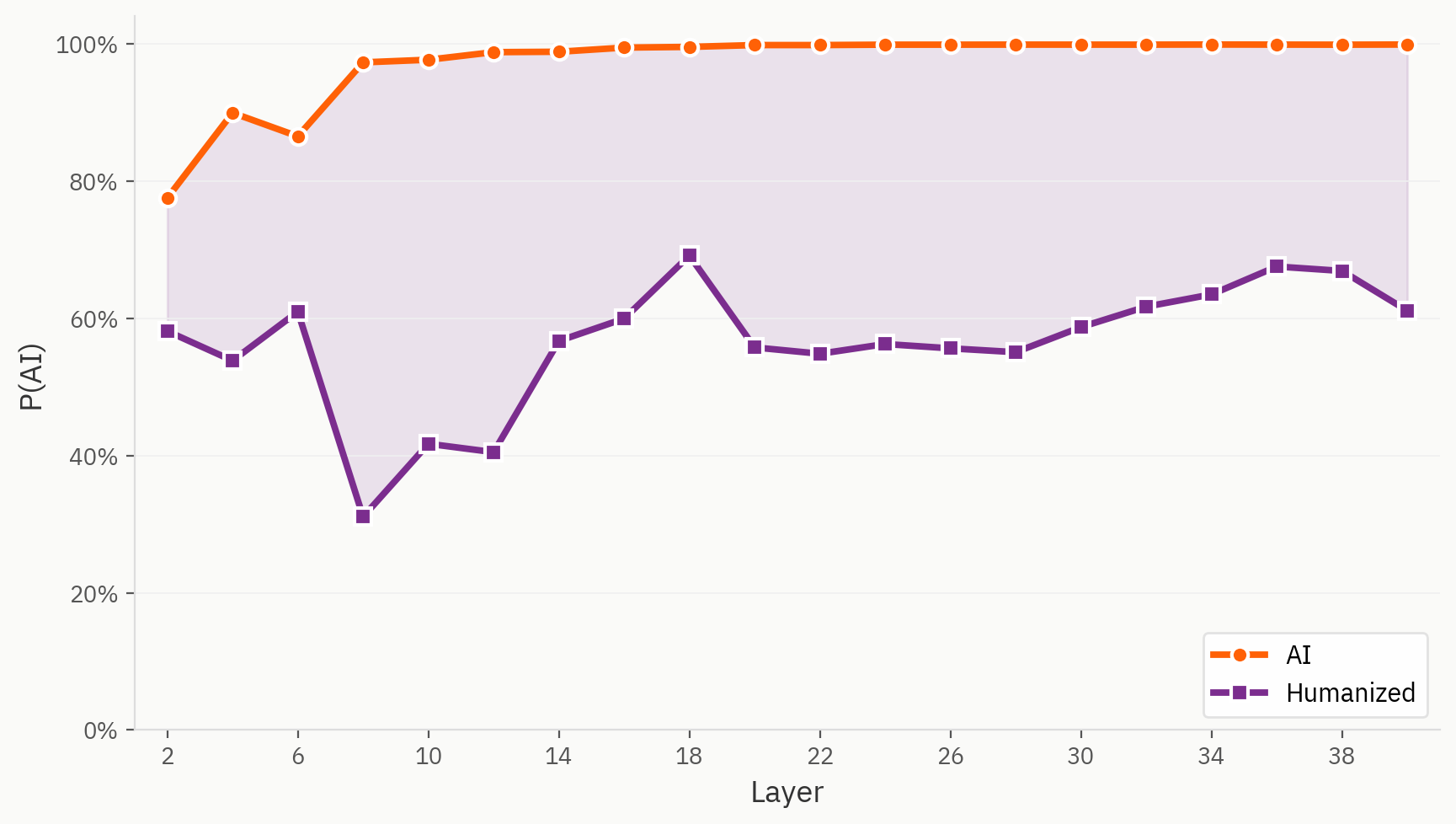
埋め込み空間におけるヒューマナイザーの位置
しかし、最終的な出力結果の背後を詳しく見てみると、ヒューマナイズされたテキストにははるかに豊かな表現が見て取れます。以下では、人間、AI、およびヒューマナイズされたテキストに対して、我々の次元削減手法を適用しています。定性的に見ると、ヒューマナイザーは活性化空間の別々の領域を占める傾向があり、人間やAIの領域の外側にクラスターを形成していることがわかります。
我々の仮説は、ヒトによるテキストのラベルがないにもかかわらず、このモデルは「ヒトによるテキスト」「人間が書いたテキスト」「AIが生成したテキスト」を区別できるというものである。しかし、最終的な評価結果では、モデルはその信号を統合せざるを得なくなり、その処理に一貫性が欠けている。
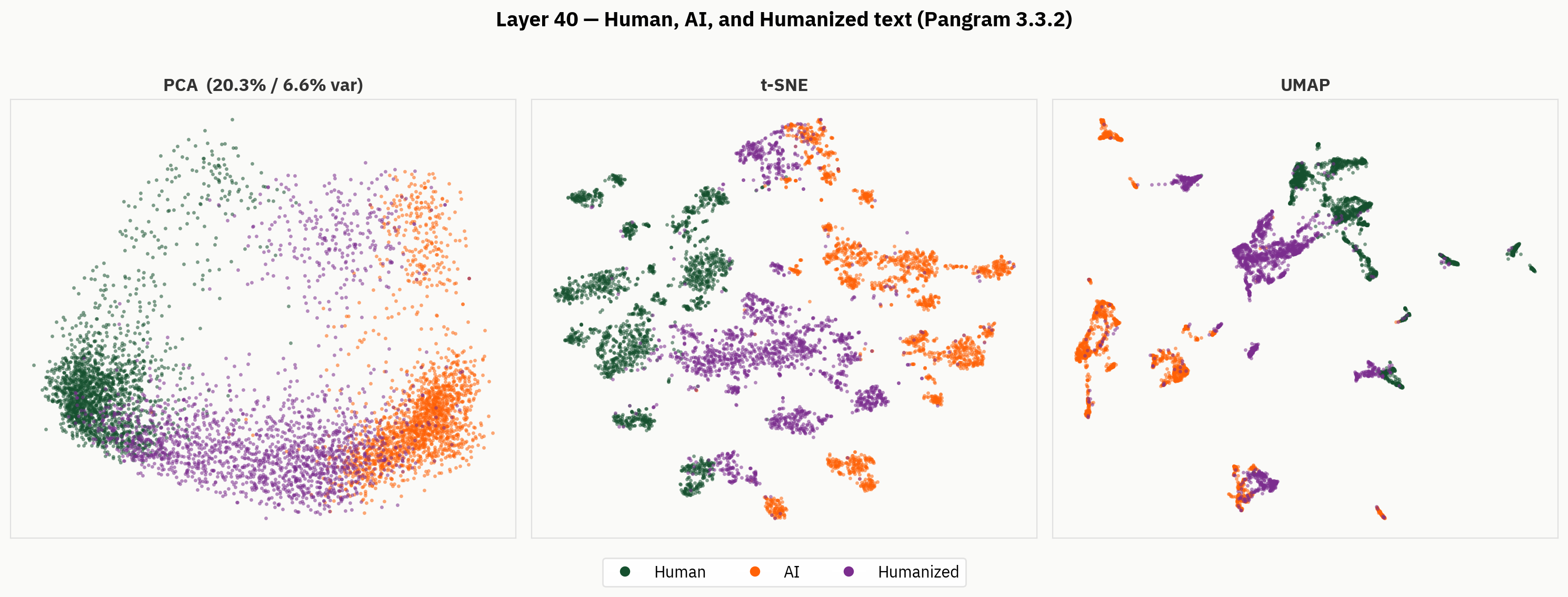
プローブ
この仮説を検証するため、AI生成テキスト、人間が作成したテキスト、および人間風テキストのラベルを用いた3値線形プローブを学習させた。このプローブは、ネットワークの初期段階で高いトップ1精度を達成し、最終的には98%で横ばいとなった。
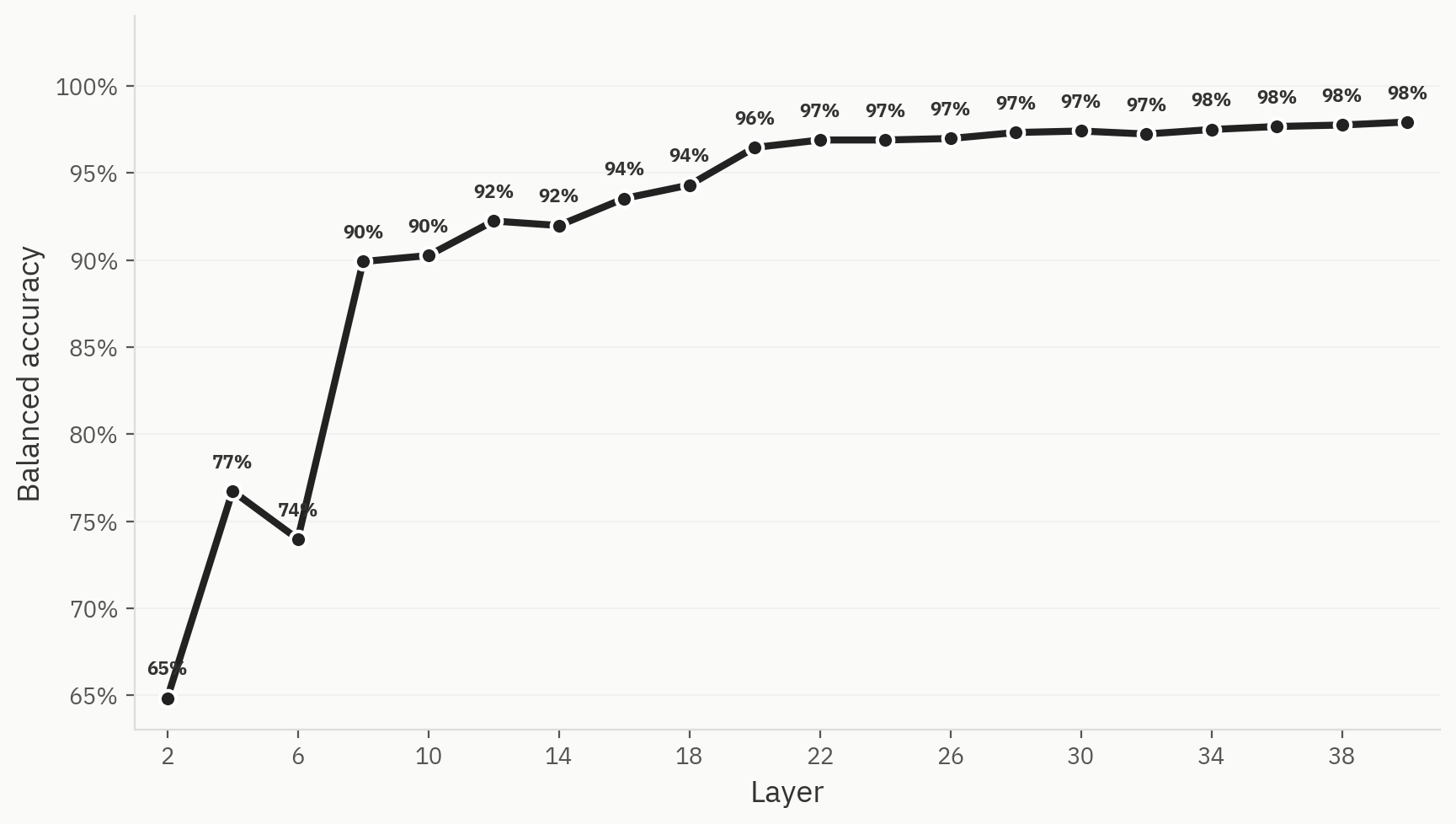
結論
本研究の結果は、パングラムの内部表現には、最終的な二値出力だけでは明らかにならない、より複雑な構造が含まれていることを示唆している。各層を横断して見ると、人間が作成した文書とAIが作成した文書が分離し、モデルファミリーごとの特徴が現れ、人間らしいテキストが活性化空間内の独自の領域を占めていることが確認できる。これらの知見はまだ初期段階のものだが、モデルがすべてを単一の検出スコアに集約する前に何を学習しているのかを理解するための有用な指針となる。
この投稿では、解釈可能性に関する取り組みのほんの第一歩を紹介したに過ぎませんが、社内では、この研究の方向性に大きな期待と関心を寄せています。
パングラム・モデルにおける解釈可能性と説明可能性について、私たちが掲げるビジョンは、次のようなものです:
- モデルの挙動について、社内の理解を深める。
- 個々のパングラムの結果について、裏付けとなる証拠とより明確な説明を提示してください。
解釈可能性やAI検出の研究、あるいは本研究に関連するその他の分野に関心をお持ちの研究者の皆様は、elyas@pangram.com までご連絡ください。
