機械学習およびデータチーム向けAI検出
機械学習エンジニアおよびデータサイエンティスト向けAI検出ツール
LLMのトレーニングとデータ選定を最適化します。99.98%の精度と高スループットのAPIパフォーマンスにより、前学習や微調整用のデータセットから合成テキストをフィルタリングし、モデルの崩壊を防ぎます。
Google、Tesla、スタンフォード大学の研究者によって開発されました。ICLRおよびメリーランド大学によって検証されています。
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")のグローバルブランドから信頼されています

















ユースケース
でモデルをトレーニングする際は、質の悪いデータを使用しないでください。
合成テキストが公開データセットを汚染しています。最も精度の高いAI検出エンジンを活用して、トレーニングパイプラインからAI生成コンテンツを排除し、コーパスの純度を維持しましょう。
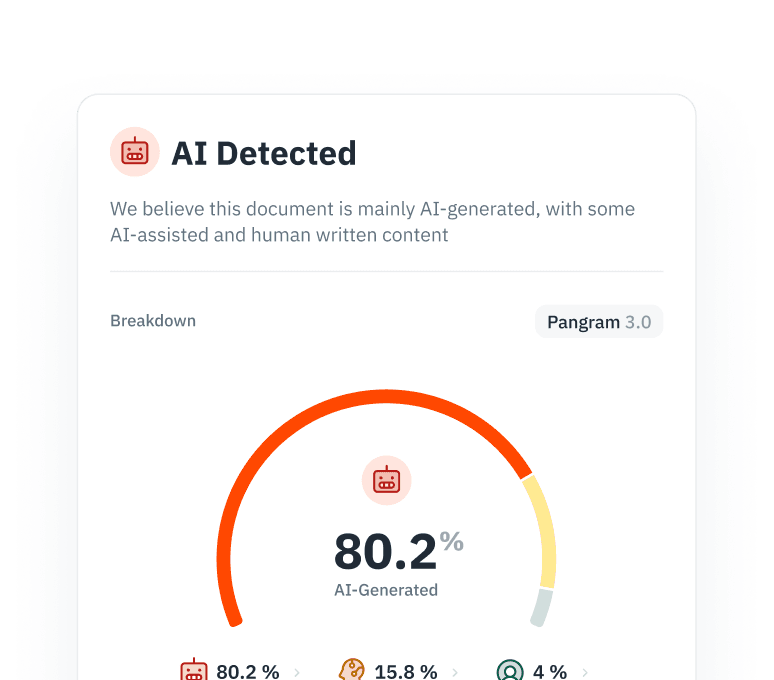
モデルの崩壊を防ぐ
AI生成コンテンツを用いた再学習は、モデルの性能と多様性を低下させます。コーパスの純度を確保するため、スクレイピングパイプラインからAIが作成したコンテンツを特定し、除外してください。
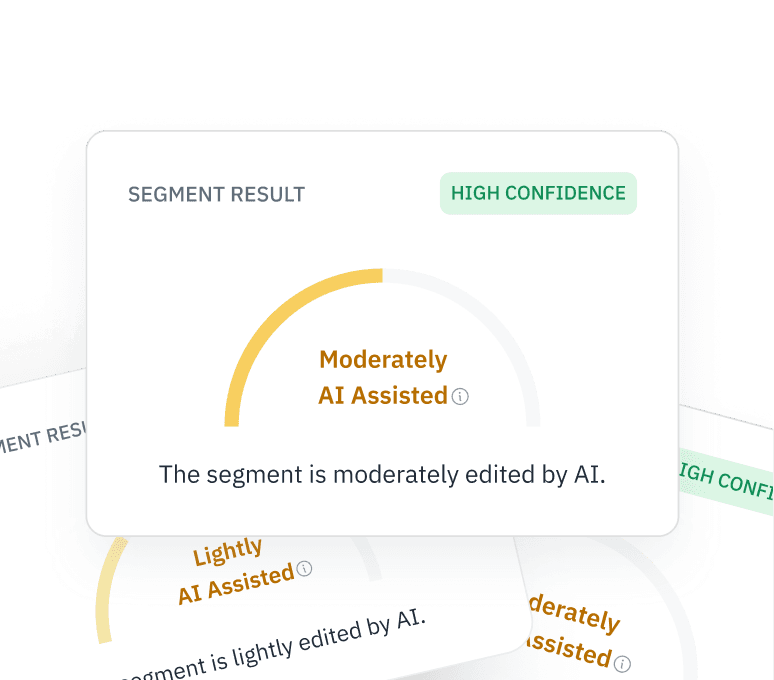
RLHF入力の確認
「Human Feedback(RLHF)」データが実際に人間によるものであることを確認してください。微調整タスクにおいて、クラウドワーカーがChatGPTを使用して回答を生成していないかを確認してください。
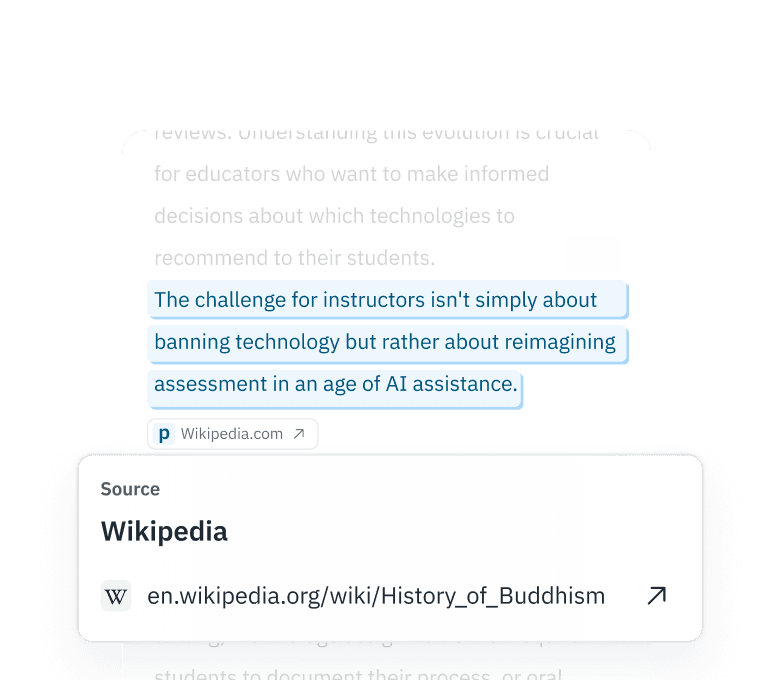
粒度の細かい解釈可能性
単純な二分法に甘んじないでください。当社のプレミアムAPIはトークン単位の確率情報を返すため、人間が編集したセグメントは保持しつつ、完全に合成された「粗悪なデータ」を排除することができます。
技術的アプローチ
が自信を持っておすすめするモデル
データフィルタリングに確かな信頼を求めるエンジニアのために開発されました。当社のモデルは、誤検知、敵対的攻撃に対する堅牢性、そして変化し続けるAIの出力に対応しています。

ハードネガティブマイニング
誤検知を最小限に抑え、貴重な人間によるデータを誤って除外しないようにするため、当システムでは「ハードネガティブ」(文体が形式的であったり、内容が反復的であったりする人間による文章)を用いて学習を行っています。
敵対的強靭性
Pangramは、言い換えられたり改変されたりしたAI生成コンテンツに対応しています。当社のモデルは、「ヒューマナイザー」や敵対的攻撃に対して学習されており、難読化された合成テキストを検出します。
将来を見据えた対策
GPT-5、Claude 3.5、Llama 3などの最新モデルから生成されたテキストを検出し、フィルタが常に最新の最先端技術(SOTA)をリードし続けることを保証します。
統合
のデータパイプライン向けに設計されています

01
Python SDK
pangram-sdk をインストールし、わずか数行のコードで Airflow または Databricks のパイプラインに検出機能を組み込むことができます。接続プーリングとエラー処理に最適化されています。
ドキュメントを表示 →
02
の高スループットAPI
膨大なデータセットを低遅延で処理します。当社のインフラストラクチャはバッチ処理に対応し、スループットを保証することで、企業向けのスクレイピング業務における数百万件のリクエストを処理します。
APIキーを取得 →
03
セキュリティおよび
への準拠
SOC 2 Type 2 認証を完全に取得しています。専用のエンドポイントと厳格なデータ保持ポリシーを提供しており、お客様の機密データを用いてトレーニングを行うことは一切ありません。
詳細はこちら →
はい。pangram-sdkをインストールすれば、わずか数行のコードで Airflow や Databricks のパイプラインに検出機能を組み込むことができます。当社の API は、高スループットなエンタープライズ向けスクレイピング作業向けに最適化されており、数百万件のリクエストを低遅延で処理可能です。
今すぐトレーニングデータをクリーンアップしましょう
モデルの崩壊を防ぎ、RLHFの入力データを検証し、データセットから合成コンテンツを99.98%の精度でフィルタリングします。
を購読して、最新情報を受け取りましょう
