Esta entrada del blog se ha publicado también en el Substack del autor. ¡Síguele aquí!
Declaración de financiación: Pangram proporcionó los créditos de OpenRouter para llevar a cabo esta investigación, y la idea original de la misma fue sugerida por Max Spero, director ejecutivo de Pangram. He hecho todo lo posible por mantener la imparcialidad y el texto que figura a continuación refleja mis opiniones sinceras.
Cuando ChatGPT salió al mercado, hubo varios casos muy sonados en los que la gente intentó utilizarlo como detector de IA, es decir, introduciendo un fragmento de texto y preguntándole directamente si había sido generado por IA o no. El Washington Post informó sobre un profesor de la Universidad de Texas A&M que había puesto un cero a varios estudiantes basándose en que ChatGPT atribuía la autoría de sus trabajos a la IA. Una profesora adjunta de la Universidad de San Francisco dijo a sus colegas que «lo único que tenemos que hacer es preguntar: “¿Has escrito tú esto?” y, a continuación, copiar y pegar el trabajo del estudiante en el cuadro de entrada», solo para escribir después una entrada de blog sobre la absurda cantidad de falsos positivos que esto generaba. Más recientemente, cuando el ganador de un concurso de relatos cortos organizado por Granta fue acusado de utilizar IA, Granta recurrió a Claude para investigar si el texto ganador había sido realmente generado por IA.
Aunque estos intentos puedan parecer ingenuos, y quizá un poco divertidos —al fin y al cabo, ChatGPT no tiene forma de verificar que ha generado un texto y debe adivinarlo basándose en las «vibraciones» (igual que haría un humano)—. Pero no es una deducción irracional para alguien sin conocimientos técnicos: ChatGPT puede escribir historias como un autor humano, y los autores humanos pueden reconocer o recordar su obra, así que, ¿por qué no ChatGPT? Además, existen otras formas de verificar la generación por IA, como SynthID para imágenes, audio y vídeo. ¿Por qué no una para el texto? La respuesta —que SynthID requiere una marca de agua detectable— no es obvia. Y lo que resulta aún más confuso es que, si le preguntas a Gemini si una imagen ha sido generada por IA, simplemente responde: «Sí, la mayor parte o la totalidad de esta imagen se ha generado o editado utilizando la IA de Google», lo que oculta la verificación de la marca de agua de SynthID y da la impresión de que Gemini puede deducirlo visualmente basándose en las «vibraciones». Así pues, para aclarar toda esta ambigüedad:
- Los modelos de lenguaje grande (LLM) carecen de memoria episódica sobre la generación de un texto, por lo que no pueden identificarlo por el mero hecho de haberlo escrito.
- Las marcas de agua en el texto sí existen —como SynthID Text de Google—, pero requieren que el texto haya sido generado por un sistema de IA participativo con la función de marca de agua activada. Por lo tanto, no es una solución universal para cualquier texto.
- Por lo tanto, la detección de texto mediante IA debe realizarse basándose en la intuición: ya sea la intuición humana, algoritmos de aprendizaje automático entrenados (como Pangram) o la intuición de un modelo de lenguaje grande (LLM).
Y, históricamente, ¡la intuición de los LLM ha sido pésima! Esto tiene mucho sentido: la primera generación de LLM dirigidos al consumidor —GPT-3.5 y GPT-4, quizá también Claude 3— se entrenaron con datos anteriores a la «inundación de IA» en Internet. Su exposición al texto generado por IA probablemente fue limitada, si no inexistente, por lo que, naturalmente, su rendimiento «zero-shot» sería deficiente. Pero esto plantea la pregunta: ¿tendrían los LLM más modernos, entrenados con datos más recientes, quizás una mejor intuición?
Adam Kucharski investigó este tema en su Substack, y los resultados iniciales son prometedores: Claude fue capaz de distinguir dos comienzos de relatos generados por IA de uno escrito por un humano, identificar diez relatos escritos por GPT-5.5 como generados por IA con una probabilidad superior al 80 %, y no asignó una probabilidad superior al 22 % de que fueran generados por IA a diez relatos extraídos de los escritos personales de Kucharski. Y lo que es aún más prometedor, Kucharski pidió a GPT-5.5 que «mejorara» cada una de sus diez historias y cinco pasaron de estar escritas por humanos a generadas por IA. Esto supone veintitrés aciertos en la clasificación directa de la IA y cinco aciertos y cinco fallos en la clasificación de la edición por IA.
Esto plantea la pregunta: ¿cuándo surgió esta capacidad de detección de la IA? Para comprobarlo, utilicé el conjunto de datos abierto «editlens-iclr» de Pangram, que contiene numerosos ejemplos de pasajes escritos por humanos y sus equivalentes generados por IA. Para empezar, seleccioné una muestra piloto de 100 pasajes —50 escritos por humanos y 50 generados por IA— y evalué una serie de modelos —tanto históricos como actuales— en cuanto a su precisión «zero-shot». Para maximizar la clasificación basada en «vibes» —la intuición que intentaba detectar—, llevé a cabo este experimento desactivando el razonamiento cuando era posible y con instrucciones estrictas de responder únicamente con una palabra. Esto dio como resultado el siguiente formato de prompt «zero-shot»:
 Formato de prompt «zero-shot»
Formato de prompt «zero-shot»
A continuación se muestran los resultados, que son bastante llamativos:
 Rendimiento «zero-shot» por fecha de lanzamiento
Rendimiento «zero-shot» por fecha de lanzamiento
Vemos que GPT-4 parte del 52 % —lo que no es mejor que el azar—, lo que se corresponde con la idea que se tenía en 2023/2024 de que la IA carecía de capacidad para detectar su propia escritura (GPT-3.5-Turbo obtuvo un 49 % y no figura en el gráfico anterior). Si avanzamos hasta la primavera y el verano de 2025, GPT-4.1 alcanza el 71 %, Sonnet 4 el 62 % y Opus 4 el 69 %. Lo que sigue a continuación es un rápido aumento de la capacidad desde mediados del verano de 2025 hasta principios de 2026, momento en el que tanto la serie GPT como la serie Claude alcanzan precisiones superiores al 90 % en esta muestra de 100 ejemplos. Este salto también se produce, aunque un poco más tarde, en la serie Qwen Plus, cuya precisión se dispara del 55 % de la versión Qwen3.5 Plus al 83 % de la Qwen3.6 Plus, lanzada solo dos meses después.
Cabe preguntarse si esta ventaja del «zero-shot» se debe principalmente a la familiaridad con el contenido generado por IA o si se trata simplemente de una diferencia de inteligencia, de modo que los modelos de vanguardia más inteligentes actúan como mejores clasificadores. Para comprobarlo, podemos observar cómo cambia la precisión al insertar ejemplos de «few-shot» (extraídos del conjunto de entrenamiento y aleatorizados por pregunta, por supuesto) en el contexto. Esto mejora nuestro formato de prompt a la siguiente plantilla de «few-shot»:
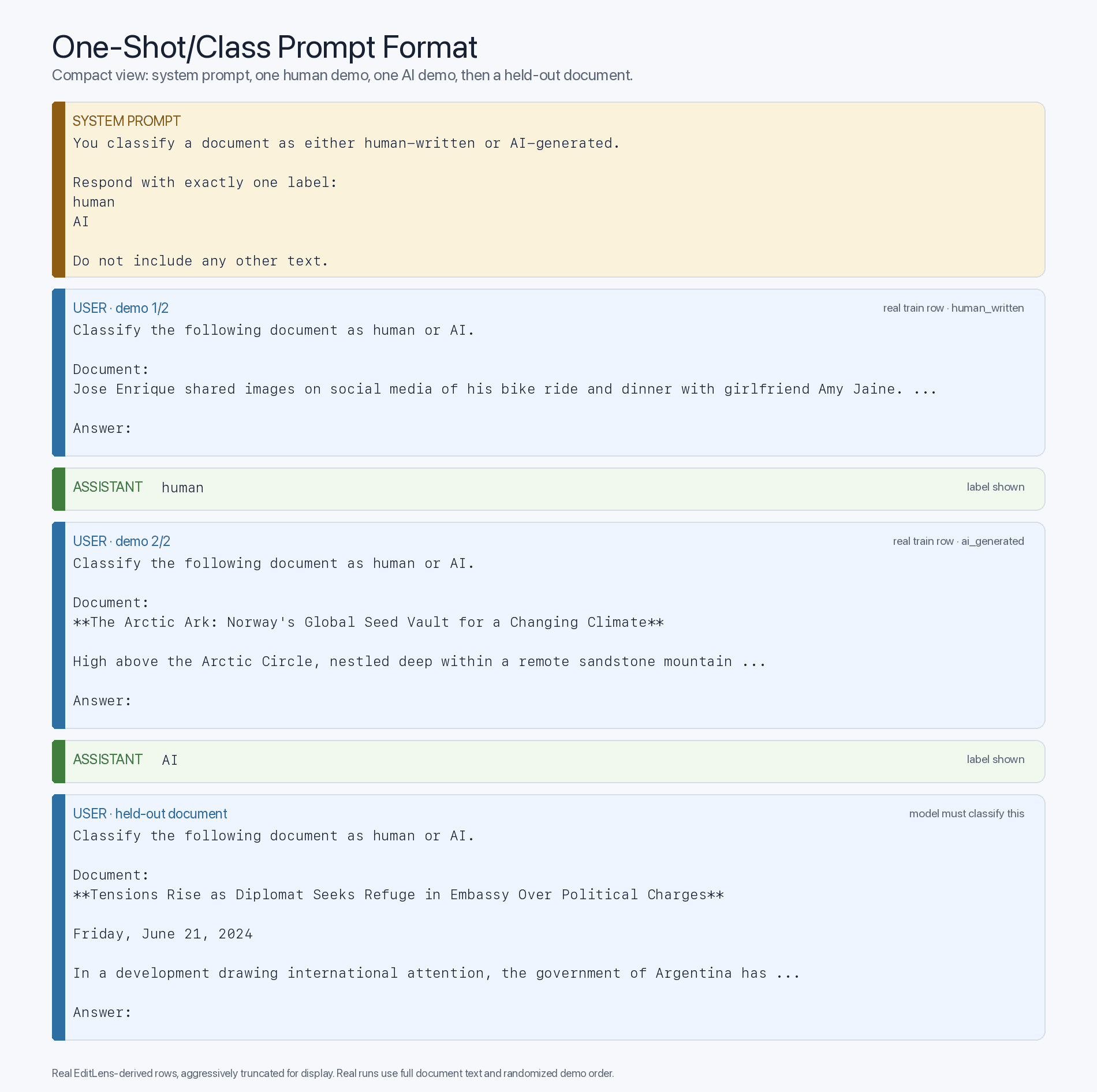
Si, en este formato de prompt de pocas muestras, los modelos más antiguos mejoran notablemente al exponerse a las correspondencias adecuadas entre entradas y etiquetas, entonces el cuello de botella es la exposición al preentrenamiento, no la inteligencia. Y eso es exactamente lo que observamos:
 Gráfico ICL de GPT por pregunta
Gráfico ICL de GPT por pregunta
Mientras que GPT-4 en modo «zero-shot» solo alcanza el 52 %, en modo «4-shot»1 alcanza el 85 %. Está claro que GPT-4 puede aprender en contexto a distinguir entre textos generados por IA y escritos por humanos; simplemente no cuenta con el conocimiento innato y preentrenado de cómo hacerlo. Esto queda subrayado por el hecho de que el rendimiento «zero-shot» mejora de forma casi monótona con respecto a la generación de modelos, mientras que el rendimiento «few-shot» se mantiene prácticamente estable a partir de ~GPT-5.1 y solo aumenta notablemente hasta el 99 % en GPT-5.5. Estos datos sugieren claramente que el ingrediente que faltaba para que los LLM se convirtieran en detectores de IA «zero-shot» medianamente decentes era simplemente disponer de datos de preentrenamiento adecuados (o ejemplos de referencia en contexto), y no ninguna limitación intrínseca de su naturaleza o inteligencia.
Para investigar más a fondo el impacto del aprendizaje en contexto con pocos ejemplos (few-shot) en la capacidad de detección de ICL, necesitaba un conjunto más difícil para extraer más información; al fin y al cabo, si los modelos de vanguardia actuales obtienen una puntuación del 95 % en una evaluación de 100 preguntas, deja de ser útil. Para construir este conjunto difícil, filtré el conjunto de datos Pangram para conservar únicamente los ejemplos que engañaron a Qwen 3.7 Plus dos veces (con temp=0,7). Esto me proporcionó 3.503 muestras generadas por IA y 763 muestras escritas por humanos, que luego equilibré por clases (mediante muestreo aleatorio uniforme) para obtener el conjunto de datos difícil definitivo, compuesto por 763 muestras generadas por IA y 763 muestras escritas por humanos.
Evalúo tanto Sonnet 4.6 como GPT-5.5 en este conjunto de datos complejo, con 0, 1, 2, 4 y 8 «shots», con el razonamiento desactivado y con el razonamiento activado (esfuerzo medio para GPT-5.5 y «pensamiento extendido simple» para Sonnet 4.6, por motivos de rentabilidad):
 Tabla del Soneto 4.6 revisada
Tabla del Soneto 4.6 revisada
 Gráfico GPT-5.5 depurado
Gráfico GPT-5.5 depurado
Vemos que GPT-5.5 supera con creces a Sonnet 4.6 en el modo «zero-shot», algo previsible dado que GPT-5.5 se lanzó en abril de 2026 y Sonnet 4.6 en febrero de 2026. Cabe destacar que esta diferencia se reduce considerablemente con ICL: mientras que (con el razonamiento desactivado) GPT-5.5 alcanza un 86,8 % en «zero-shot» frente al 72,9 % de Sonnet 4.6, con 8 ejemplos, GPT-5.5 alcanza un 96,2 % frente al 93,8 % de Sonnet 4.6. Esto refuerza aún más la idea de que gran parte de la detección de IA es una capacidad que, al igual que casi cualquier otro tipo de clasificación de texto, puede adquirirse en contexto.
Cabe destacar que, si bien el razonamiento supone una mejora significativa de unos pocos puntos porcentuales para GPT-5.5, solo ayuda realmente a Sonnet 4.6 en el régimen «zero-shot» (aportando un +2,2 %) y, a partir de ahí, apenas le perjudica o apenas le ayuda. Las pruebas estadísticas lo confirman: tras la corrección de Bonferroni, el beneficio que obtiene GPT-5.5 del razonamiento sigue siendo estadísticamente significativo con 0, 1, 2 y 8 «shots», mientras que Sonnet 4.6 solo presenta un efecto significativo con cero «shots».
Esto parece indicar que, si bien el cálculo en tiempo de prueba puede ayudar a la clasificación de la escritura generada por IA, solo algunas familias de modelos cuentan con la capacidad de entrenamiento necesaria para aplicarlo de forma eficaz en comparación con la intuición inmediata, y las mejoras no son muy significativas en comparación con el simple hecho de proporcionar más ejemplos en contexto a partir de los cuales aprender. En futuros trabajos se podría evaluar GPT-5.5 en niveles de razonamiento «alto» o «xalto» para comprobar si las mejoras se mantienen.
En resumen, hemos visto que los modelos de lenguaje grandes (LLM) modernos pueden distinguir con éxito los textos generados por IA de los escritos por humanos, que esta capacidad se debe probablemente a una mayor exposición durante el preentrenamiento a contenidos generados por IA, y que se beneficia ligeramente de la potencia de cálculo en el momento de la prueba, pero en gran medida de un mayor número de ejemplos en contexto (hasta el punto de que los LLM más antiguos, como GPT-4, pueden aprenderlo partiendo de un nivel de referencia de «zero-shot» equivalente al azar). Esto contradice la narrativa anterior de que ChatGPT era incapaz de decirte si un texto había sido generado por IA. Sin embargo, en la práctica yo seguiría sin utilizarlos como detectores de IA: en el conjunto de datos difícil, el modelo con mejor rendimiento —el GPT-5.5 con razonamiento medio— presenta una tasa de falsos positivos del 4,59 %, lo cual es inaceptable incluso para un uso ocasional (a modo de contexto, cabe señalar que un estudio reciente reveló que la tasa media de falsos positivos de cinco anotadores humanos expertos era del 5,6 %, pero que un conjunto de estos anotadores presentaba una tasa de falsos positivos del 0 %). Si buscas un detector fiable, te recomendaría Pangram, con las salvedades que comento en mi artículo «En defensa de Pangram ». En cualquier caso, sigo encontrando esta capacidad bastante intrigante, y me ha parecido importante documentarla, dado que la opinión generalizada durante los últimos años ha sido que los LLM son totalmente incapaces de detectar textos generados por otros LLM. En cambio, es mejor considerar que los LLM se sitúan, a grandes rasgos, en un nivel de «humano competente a experto» a la hora de detectar textos generados por IA. Son bastante precisos, pero presentan tasas de falsos positivos de un solo punto porcentual, lo que hace que sus acusaciones no sean pasibles de acción.
Notas a pie de página
-
Ten en cuenta que, en este caso, «4-shot» se refiere a 4 ejemplos generados por IA y 4 ejemplos generados por humanos, no a un total de 4 ejemplos. ↩

Nathan Breslow —cuyo alias en Internet es N8Programs— es estudiante de grado en Matemáticas Aplicadas en la Universidad Johns Hopkins. Además, trabaja en el aprendizaje contextual en modelos de lenguaje grandes (LLM) en el Intelligence Amplification Lab, colabora en marcos de inferencia locales y realiza el preentrenamiento de modelos de lenguaje en modalidades exóticas. Las opiniones aquí expresadas son exclusivamente suyas.
Lecturas relacionadas

Cómo detectar las reseñas generadas por IA

La IA está escribiendo obras de ficción galardonadas

Cómo utiliza Gradpilot el pangram para ayudar a los estudiantes a encontrar su voz

¿Qué detector de IA es el más preciso? 30 herramientas analizadas (2026)
Cada día se publican 60 000 artículos de noticias generados por IA

¿En qué se diferencia Pangram de GPTZero?
