Bu blog yazısı, yazarın Substack hesabından da yayınlanmıştır. Onu buradan takip edin!
Finansman Açıklaması: Bu araştırmanın yürütülmesi için OpenRouter kredileri Pangram tarafından sağlanmıştır ve bu araştırmanın orijinal fikri, Pangram’ın CEO’su Max Spero tarafından önerilmiştir. Tarafsız kalmak için elimden geleni yaptım ve aşağıdaki metin tamamen kendi görüşlerimi yansıtmaktadır.
ChatGPT ilk çıktığı zamanlarda, insanların onu bir yapay zeka tespit aracı olarak kullanmaya çalıştığı birkaç çok konuşulan olay yaşandı — yani, sisteme bir metin girip, bunun yapay zeka tarafından üretilip üretilmediğini doğrudan soruyorlardı. Washington Post, ChatGPT’nin öğrencilerin ödevlerinin yazarı olduğunu iddia etmesi gerekçesiyle birçok öğrenciye sıfır veren bir Texas A&M profesöründen bahsetmişti. San Francisco Üniversitesi’nden bir yardımcı doçent ise meslektaşlarına “Tek yapmamız gereken ‘Bunu sen mi yazdın?’ diye sormak ve ardından öğrencinin çalışmasını komut kutusuna kopyalayıp yapıştırmak” demişti — ancak daha sonra bunun ne kadar çok sayıda yanlış pozitif sonuç ürettiğini anlatan bir blog yazısı kaleme almıştı. Daha yakın zamanda, Granta dergisi tarafından düzenlenen bir kısa öykü yarışmasının galibi yapay zeka kullandığı iddiasıyla suçlandığında, Granta, kazanan metnin gerçekten yapay zeka tarafından üretilip üretilmediğini araştırmak için Claude’u kullandı.
Bu girişimler naif ve belki de biraz komik görünebilir – ne de olsa ChatGPT, bir metni kendisinin ürettiğini doğrulamanın bir yolu yoktur ve (tıpkı bir insanın yapacağı gibi) izlenimlere dayanarak tahminde bulunmak zorundadır. Ancak teknik bilgisi olmayan bir kişinin bu sonuca varması mantıksız değildir: ChatGPT, insan bir yazar gibi hikayeler yazabilir ve insan yazarlar kendi eserlerini tanıyabilir/hatırlayabilir, öyleyse neden ChatGPT yapamasın? Dahası, görüntüler, ses ve videolar için SynthID gibi yapay zeka tarafından üretildiğini doğrulayan başka yöntemler de mevcuttur. Neden metinler için de bir yöntem olmasın? SynthID’nin tespit edilebilir bir filigran gerektirdiği gerçeği, ilk bakışta açık değildir. Daha da kafa karıştırıcı olan ise, Gemini’ye bir görüntünün yapay zeka tarafından üretilip üretilmediğini sorarsanız, basitçe “Evet, bu görüntünün çoğu veya tamamı Google AI kullanılarak üretildi veya düzenlendi.” der — bu da SynthID filigran doğrulamasını gizler ve Gemini’nin bunu sadece görsel izlenimlere dayanarak çıkarabileceği izlenimini verir. Öyleyse, tüm bu belirsizliği açıklığa kavuşturmak gerekirse:
- Büyük dil modelleri (LLM’ler), bir metni oluşturmaya dair epizodik bir hafızaya sahip olmadıkları için, onu yazmış olmaları nedeniyle o metni tanımlayamazlar.
- Metin filigranlama teknolojisi gerçekten mevcuttur — örneğin Google’ın SynthID Text’i gibi — ancak bunun için metnin, filigranlama özelliği etkinleştirilmiş katılımcı bir yapay zeka sistemi tarafından üretilmiş olması gerekir. Dolayısıyla bu, herhangi bir metin için evrensel bir çözüm değildir.
- Dolayısıyla, yapay zeka ile metin algılama işlemi sezgi yoluyla gerçekleştirilmelidir; bu sezgi, insan sezgisi, eğitilmiş makine öğrenimi algoritmaları ( Pangram gibi) ya da bir LLM’nin sezgisi olabilir.
Ve tarihsel olarak, büyük dil modellerinin (LLM) sezgileri kötü olmuştur! Bu son derece mantıklıdır – tüketicilere yönelik ilk nesil büyük dil modelleri – GPT-3.5 ve GPT-4, belki de Claude 3 – hepsi internetin yapay zeka ile dolup taşmasından önceki verilerle eğitilmişti. Yapay zeka tarafından üretilen metinlere maruz kalmaları, hiç olmasa bile muhtemelen sınırlıydı; dolayısıyla elbette sıfır deneme performansları zayıf olacaktı. Ancak bu, şu soruyu gündeme getiriyor: Daha güncel verilerle eğitilmiş, daha modern LLM’ler belki de daha iyi sezgilere sahip olabilir mi?
Adam Kucharski, Substack platformunda bu konuyu araştırdı ve ilk sonuçlar umut verici: Claude, yapay zeka tarafından üretilen iki hikâye girişini insan tarafından yazılmış bir tanesinden ayırt edebildi; GPT-5.5 tarafından yazılmış on hikâyeyi %80’in üzerinde bir olasılıkla yapay zeka ürünü olarak tanımladı ve Kucharski’nin kişisel yazılarından seçilen on hikâyeye ise yapay zeka ürünü olma olasılığı olarak en fazla %22 verdi. Daha da umut verici olan ise, Kucharski’nin GPT-5.5’ten on öyküsünün her birini “iyileştirmesini” istemesi ve bunlardan beşinin insan tarafından yazılmıştan yapay zeka tarafından üretilene dönüştürülmesiydi. Bu, doğrudan yapay zeka sınıflandırmasında yirmi üç başarı, yapay zeka düzenleme sınıflandırmasında ise beş başarı ve beş başarısızlık anlamına geliyor.
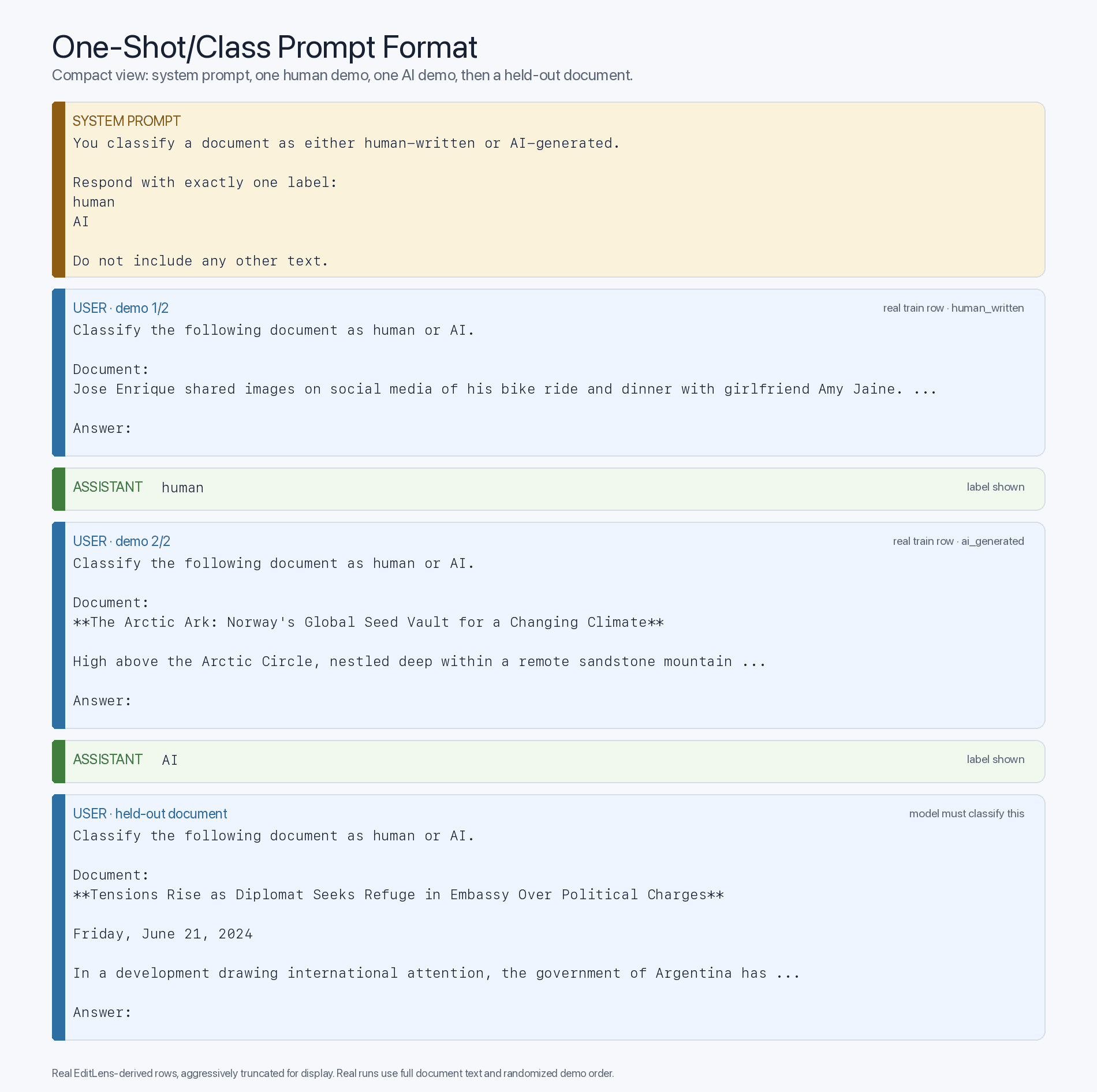
Bu da şu soruyu gündeme getiriyor: Bu yapay zeka algılama yeteneği ne zaman ortaya çıktı? Bunu test etmek için, insan tarafından yazılmış metinlere ve aynı metinlerin yapay zeka tarafından üretilmiş kopyalarına dair bol miktarda örnek içeren Pangram’ın açık kaynaklı editlens-iclr veri setini kullandım. İlk olarak, 50’si insan, 50’si yapay zeka tarafından yazılmış olmak üzere 100 metinden oluşan bir pilot örneklem aldım ve hem geçmişte geliştirilmiş hem de güncel bir dizi modeli sıfır örnekle doğruluk açısından değerlendirdim. Tespit etmeye çalıştığım sezgiye dayalı sınıflandırmayı en üst düzeye çıkarmak için, bu deneyi mümkün olduğunda akıl yürütmeyi devre dışı bırakarak ve yanıtın yalnızca tek kelimeden oluşması yönünde katı talimatlar vererek gerçekleştirdim. Bu, aşağıdaki sıfır deneme komut biçimini ortaya çıkardı:
 Sıfır denemeli komut biçimi
Sıfır denemeli komut biçimi
Sonuçlar aşağıda gösterilmiştir ve oldukça dikkat çekicidir:
 Yayın tarihine göre sıfır deneme performansı
Yayın tarihine göre sıfır deneme performansı
GPT-4’ün %52’den başladığını görüyoruz – bu, şansla aynı seviyede – ki bu da 2023/2024’teki, yapay zekanın kendi yazdıklarını algılama yeteneğine sahip olmadığına dair sezgiyle örtüşüyor (GPT-3.5-Turbo %49’luk bir sonuç elde etti ve yukarıdaki grafikte yer almıyor). 2025 ilkbahar ve yaz aylarına geldiğimizde ise GPT-4.1 %71, Sonnet 4 %62 ve Opus 4 %69 oranlarına ulaşıyor. Bunu, 2025 yaz ortasından 2026 başlarına kadar süren hızlı bir yetenek artışı izliyor; bu dönemde hem GPT hem de Claude serileri, bu 100 örneklik kesitte %90’ın üzerinde doğruluk oranlarına ulaşıyor. Bu sıçrama, biraz daha geç de olsa, Qwen Plus serisinde de yaşanır; Qwen3.5 Plus sürümündeki %55 doğruluk oranı, sadece iki ay sonra piyasaya sürülen Qwen3.6 Plus sürümünde %83’e fırlar.
Bu sıfır atış avantajının, esas olarak yapay zeka tarafından üretilen içeriğe aşinalıkla mı açıklanabileceği, yoksa sadece zeka farkından mı kaynaklandığı – yani daha akıllı öncü modellerin daha iyi sınıflandırıcılar olarak işlev görmesi – merak edilebilir. Bunu test etmek için, bağlama (tabii ki eğitim kümesinden alınan ve her soru için rastgele seçilen) az atış örneklerinin eklenmesinin doğruluğu nasıl değiştirdiğini inceleyebiliriz. Bu, komut biçimini aşağıdaki az atış şablonuna yükseltir:
Eğer bu “az sayıda örnek” komut biçimi kapsamında, eski modeller uygun girdi-etiket eşlemelerine maruz kaldıklarında performanslarında çarpıcı bir iyileşme gösterirlerse, o zaman darboğaz ön eğitim sürecidir, zeka değil. Ve tam da bunu gözlemliyoruz:
 Soru başına GPT ICL grafiği
Soru başına GPT ICL grafiği
GPT-4’ün sıfır örnekle (zero-shot) performansı yalnızca %52 iken, 4 örnekle (4-shot)1%85'e ulaşıyor . GPT-4'ün, bağlam içinde AI tarafından üretilen metinlerle insan tarafından yazılan metinleri ayırt et meyi öğrenebileceği açıktır — sadece bunu nasıl yapacağına dair doğuştan gelen, önceden eğitilmiş bir bilgiye sahip değildir. Bu durum, sıfır atış performansının model nesli ilerledikçe neredeyse monoton bir şekilde iyileşmesi, ancak az atış performansının ~GPT-5.1'den sonra neredeyse sabit kalması ve ancak GPT-5.5'te %99'a kadar belirgin bir artış göstermesiyle vurgulanmaktadır. Bu kanıtlar, LLM’lerin (büyük dil modelleri) yarı-makul düzeyde sıfır atış yapay zeka dedektörleri haline gelmeleri için eksik olan unsurun, doğaları veya zekalarının içsel bir kısıtlaması değil, sadece uygun ön eğitim verileri (veya bağlam içinde altın değerinde örnekler) olduğunu güçlü bir şekilde ortaya koymaktadır.
Bağlam içi az örnekle öğrenmenin ICL algılama yeteneği üzerindeki etkisini daha derinlemesine incelemek için, daha fazla sinyal elde edebilmek amacıyla daha zor bir veri kümesine ihtiyacım vardı — ne de olsa, modern öncü modeller 100 soruluk bir değerlendirmede %95 puan alıyorsa, bu yöntem artık yararlı olmaktan çıkar. Bu zor veri kümesini oluşturmak için, Pangram veri kümesini filtreleyerek yalnızca Qwen 3.7 Plus’ı (temp=0,7 değerinde) iki kez yanıltan örnekleri elinde tuttum. Böylece 3.503 adet yapay zeka tarafından üretilmiş örnek ve 763 adet insan tarafından yazılmış örnek elde ettim; daha sonra bunları (tekdüze rastgele örnekleme yoluyla) sınıf dengeleme işleminden geçirerek, 763 adet yapay zeka tarafından üretilmiş örnek ve 763 adet insan tarafından yazılmış örnekten oluşan nihai zor veri setini oluşturdum.
Bu zor veri seti üzerinde, hem Sonnet 4.6’yı hem de GPT-5.5’i, 0, 1, 2, 4 ve 8 shot değerlerinde, akıl yürütme özelliği kapalı ve açık olarak (maliyet-etkinlik açısından GPT-5.5 için orta düzeyde çaba, Sonnet 4.6 için basit genişletilmiş düşünme) değerlendiriyorum:
 Temizlenmiş Sonnet 4.6 tablosu
Temizlenmiş Sonnet 4.6 tablosu
 Temizlenmiş GPT-5.5 tablosu
Temizlenmiş GPT-5.5 tablosu
GPT-5.5’in Sonnet 4.6’yı sıfır örnekleme performansında açık ara geride bıraktığını görüyoruz; bu durum, GPT-5.5’in Nisan 2026’da, Sonnet 4.6’nın ise Şubat 2026’da piyasaya sürülmüş olmasından dolayı öngörülebilir bir sonuçtur. Dikkat çeken nokta, bu farkın ICL ile büyük ölçüde azalmasıdır; (akıl yürütme kapalıyken) GPT-5.5, Sonnet 4.6’nın %72,9’una karşılık %86,8 zero-shot elde ederken, 8 denemeyle GPT-5.5 %96,2’ye, Sonnet 4.6 ise %93,8’e ulaşmaktadır. Bu durum, yapay zeka algılamanın büyük bir kısmının, neredeyse diğer tüm metin sınıflandırma türleri gibi, bağlam içinde kazandırılabilen bir yetenek olduğunu bir kez daha teyit etmektedir.
Dikkat çeken nokta, akıl yürütmenin GPT-5.5 için birkaç yüzde puanı kadar önemli bir artış sağlarken, Sonnet 4.6’ya yalnızca sıfır atış rejiminde (+%2,2) gerçekten fayda sağladığı ve sonrasında ya çok az zarar verdiği ya da çok az fayda sağladığıdır. İstatistiksel testler bunu doğrulamaktadır: Bonferroni düzeltmesinden sonra, GPT-5.5’in akıl yürütmeden elde ettiği fayda 0, 1, 2 ve 8 denemede istatistiksel olarak anlamlı kalırken, Sonnet 4.6’nın etkisi yalnızca sıfır denemede anlamlıdır.
Bu durum, test aşamasındaki hesaplamaların yapay zeka ile yazım sınıflandırmasına yardımcı olabileceğini, ancak yalnızca bazı model ailelerinin bunu anlık sezgiye kıyasla etkili bir şekilde uygulayabilecek eğitim ve yeteneğe sahip olduğunu ve öğrenme için bağlam içinde daha fazla örnek sunmaya kıyasla elde edilen kazançların çok büyük olmadığını gösteriyor gibi görünüyor. Gelecekteki çalışmalarda, kazançların devam edip etmediğini görmek için GPT-5.5’i yüksek veya xyüksek akıl yürütme seviyelerinde test edilebilir.
Özetle, modern büyük dil modellerinin (LLM’ler) yapay zeka tarafından üretilen metinleri insan tarafından yazılanlardan başarıyla ayırt edebildiğini, bu yeteneğin muhtemelen ön eğitim aşamasında yapay zeka tarafından üretilen içeriğe daha fazla maruz kalmalarından kaynaklandığını ve test aşamasındaki hesaplama gücünden biraz, ancak bağlam içi örneklerin sayısının artmasından büyük ölçüde faydalandığını gördük (GPT-4 gibi eski LLM’lerin bunu sıfır denemeli, tesadüf düzeyindeki bir temel seviyeden öğrenebildiği ölçüde). Bu bulgular, ChatGPT’nin bir metnin yapay zeka tarafından üretilip üretilmediğini ayırt edemediği yönündeki eski anlatıya ters düşmektedir. Bununla birlikte, pratikte bunları yapay zeka tespit aracı olarak yine de kullanmazdım — zor set üzerinde en iyi performansı gösteren model - orta düzeyde akıl yürütme yeteneğine sahip GPT-5.5, %4,59 oranında yanlış pozitif sonuç veriyor ki bu, sıradan kullanım için bile kabul edilemez bir oran (bağlam olarak, yakın zamanda yapılan bir çalışmada beş uzman insan etiketleyicinin ortalama yanlış pozitif oranının %5,6 olduğu , ancak bu etiketleyicilerin bir araya getirilmesiyle oluşturulan bir grubun yanlış pozitif oranının %0 olduğu ortaya çıkmıştır). Güvenilir bir tespit aracı arıyorsanız, “Pangram’ın Savunması” başlıklı makalemde ele aldığım uyarıları göz önünde bulundurarak Pangram’ı öneririm. Her ne olursa olsun, bu yeteneği hâlâ oldukça ilgi çekici buluyorum — ve son birkaç yıldır yaygın kanı, LLM’lerin LLM tarafından üretilen metinleri tespit etmede tamamen yetersiz olduğu yönünde olduğu için, bunu belgelemenin önemli olduğunu düşündüm. Bunun yerine, LLM’leri AI tarafından yazılmış metinleri tespit etme konusunda kabaca “iyi ila uzman düzeyinde bir insan” olarak modellemek daha doğrudur. Oldukça doğrudurlar, ancak yüzde bir civarında yanlış pozitif oranları nedeniyle, ortaya koydukları suçlamalar eyleme geçirilebilir değildir.
Dipnotlar
-
Burada “4-shot” ifadesinin, toplam 4 örnek değil, 4 yapay zeka örneği ve 4 insan örneği anlamına geldiğini unutmayın. ↩

Nathan Breslow — çevrimiçi takma adı N8Programs — Johns Hopkins Üniversitesi’nde uygulamalı matematik okuyan bir lisans öğrencisidir. Ayrıca, Intelligence Amplification Lab’da büyük dil modellerinde (LLM) bağlam içi öğrenme üzerine çalışmakta, yerel çıkarım çerçevelerine katkıda bulunmakta ve egzotik modalitelerde dil modellerini ön eğitmektedir. Burada ifade edilen görüşler kendisine aittir.
İlgili makaleler

Yapay zeka tarafından yazılmış yorumları nasıl ayırt edersiniz?

Yapay zeka, ödüllü kurgu eserleri yazıyor

Gradpilot, öğrencilerin kendi seslerini bulmalarına yardımcı olmak için Pangram'ı nasıl kullanıyor?

Hangi AI Algılayıcı En Doğru Sonuçları Veriyor? Test Edilen 30 Araç (2026)
Her gün 60.000 adet yapay zeka tarafından üretilen haber makalesi yayınlanıyor

Pangram, GPTZero ile karşılaştırıldığında nasıl bir performans sergiliyor?
adresinden güncellemelerimize abone olun
