
在全字母句空间中的视觉体验
探索 Pangram 3.3.2 的内部表示
作者:埃利亚斯·马斯鲁尔、凯瑟琳·泰和布拉德利·埃米
2026年6月
引言
自2022年ChatGPT问世以来,人工智能辅助写作的发展速度令人瞠目。由于人工智能生成的文本如今已广泛出现在我们阅读的各类内容中,很明显,某些形式的写作一旦由机器生成,其价值便会大打折扣。在学术界,论文的宗旨在于培养学生的推理能力;而在市场领域,产品评论之所以有价值,正是因为它们反映了其他人的使用体验。
Pangram 是一家致力于针对这一问题构建最先进的人工智能检测模型的研究公司。我们的旗舰产品是一款人工智能文本检测模型,具有业界领先的低误报率、多语言处理能力,并能区分由人工智能生成和由人工智能辅助的内容。
自2024年发布首份白皮书以来,我们一直处于一个独特的观察位置,见证了一波又一波的人工智能技术进步。我们的研究人员曾与过于严格的内容过滤机制作斗争,也经历过不少模式坍缩现象,并避开了接连不断的破折号和“delve”这个词。
我们的旗舰模型是一个针对该序列分类任务进行微调的大语言模型(LLM)。我们没有使用困惑度或突发性等自定义指标,也没有进行任何手动特征提取。我们确实有一款面向客户的产品名为“AI Phrases”,通过该产品,我们会向用户提供关于在AI文本中出现频率较高的短语的信息。但这些信息并未直接作为模型的特征使用。过了一段时间,人们不禁会产生好奇:模型究竟看到了什么?
对我们这些研究人员来说,这个问题至关重要。我们有强烈的动力去防止模型走捷径、修正模型的意外行为,并深入理解这一问题。在本文中,我们将概述我们利用文档级分析开展的可解释性研究初步工作。
数据
我们利用生产训练集中同域的保留样本构建了一个可解释性数据集。本页面的交互式探索工具使用了一个包含 5,000 份文档的平衡子集,其中人类和 AI 生成的文档各占一半,并分布在 20 个偶数层中。这些 AI 样本涵盖了用于分类器探测的六个模型家族中的以下模型变体。
模型
- Claude 3.7 十四行诗
- 克劳德十四行诗4
- 克劳德·索内特 4.5
- 克劳德·作品4
- 克劳德 作品4.1
- 克劳德 作品4.5
- GPT-3.5 Turbo(2023年11月)
- GPT-3.5 Turbo(2024年1月)
- GPT-4(2023年3月)
- GPT-4(2023年6月)
- GPT-4o
- GPT-5
- GPT-5.1
- GPT-5.2
- o1
- Gemini 2.0 Flash
- 双子座2.5闪存
- 双子座2.5专业版
- Gemini 3 Pro
- DeepSeek R1
- DeepSeek V3
- Qwen 2.5 7B
- Qwen 2.5 72B
- Qwen 3 235B
- Llama 3.1 8B
- Llama 3.1 70B
源域名
- 新闻
- 科学摘要
- 产品评论
- 商业评论
- Reddit 创意写作
- Reddit ELI5
- 书籍(自出版)
- 书籍(古腾堡计划)
- 维基百科(英文版)
- 维基百科(多语言版)
- Lang-8(ESL)
Pangram 3.3.2 概述
Pangram 3.3.2 是 Pangram Labs 于 2026 年发布的一款 AI 检测模型。它采用与 Pangram 3.3 相同的底层模型,并通过后续的 bug 修复提升了性能。Pangram 3.3 作为 Pangram 3.2 的继任者,在检测新型大语言模型(LLM)生成的内容、拟人化文本以及长篇 AI 生成内容时提高了召回率,同时降低了对非母语英语写作的误报率。
模特卡阅读“全字母句”3.3 示例卡查看 Pangram 3.3.2 的发布详情。阅读文章可解释性相关工作仍在进行中。在本文中,我们还将我们的方法追溯性地应用于 Pangram 3.2 和 Pangram 3.1。
方法
激活
EditLens 架构是一种基于桶的分类系统,可简化为单一的 ai_assistance_score. 在本项目中,我们忽略模型的最终输出结果,而是专注于模型所学习的内部表征。为了探究这些表征,我们通过对模型进行前向传播(使用给定的输入文档),并在多个内部层保存模型的隐藏表征,从而收集激活值。在本项目中,我们针对网络中每个偶数层,提取了每篇文档的激活值。
降维
每个提取的激活向量均为5,120维。为了更好地理解这些表示,我们采用了多种降维技术。
PCA
主成分分析(PCA)是最简单的线性投影:它在激活空间中寻找方差最大的方向。在本项目中,我们发现,在网络的末端,大部分方差都包含在主成分1和主成分2中,因此我们将它们相互绘制在图上。
UMAP
UMAP 提供了一种旨在保留邻域结构的非线性视图。如果两个文档在模型的内部空间中位置相近,UMAP 会尽量让它们在二维空间中也保持相近。不过,不应过度解读这些轴线以及簇之间的确切距离。
t-SNE
t-SNE 是一种擅长揭示局部聚类的非线性投影方法。针对本项目的目标,我们利用 t-SNE 来探究:随着网络层数的增加,那些在语义上重要的群体(例如模型家族或“人类/AI”标签)是否会形成肉眼可见的聚类。
线性探头
我们使用线性探针来量化从降维方法中观察到的定性结果。对于每一层,我们考察一个简单的分类器能否根据该层的激活向量恢复目标标签。探针准确率越高,就意味着相关区分已经编码在表征空间中一个可通过线性方式访问的方向上。
人工智能检测任务
二进制精度
为了理解网络在运行过程中是如何实现最终类别的区分的,我们在每一层训练线性探针。我们使用500个样本进行训练,其中人类和AI样本各占一半,并采用80:20的训练/测试划分比例。 我们发现,即使在网络的早期阶段,性能已经非常出色:在第2层之后,准确率直接达到了0.83。这符合我们的直觉,因为“词袋”模型通常是AI检测任务中可行的基线模型。在整个网络中,准确率持续提升,直至在第24层达到1.0的峰值。
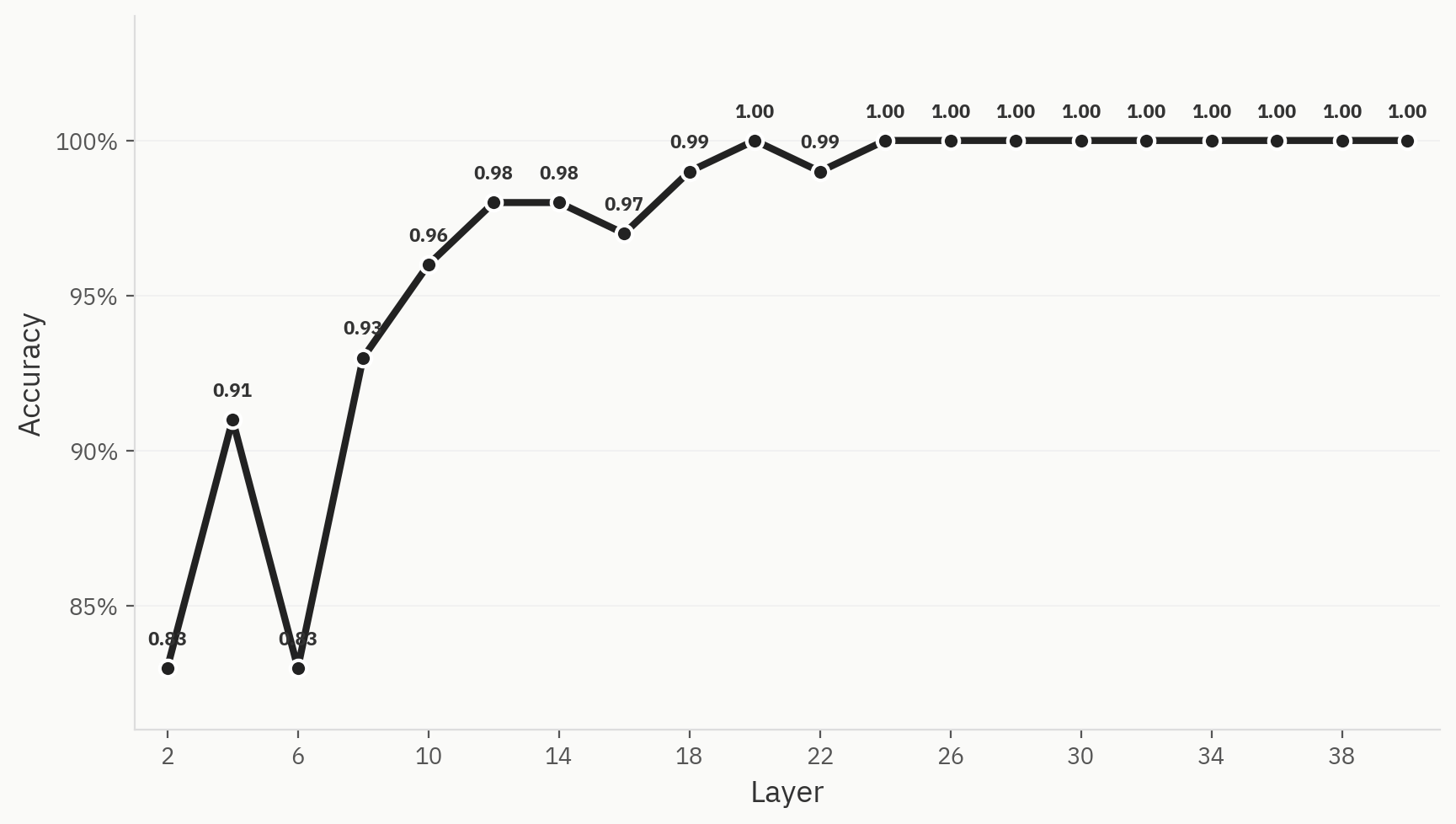
图3在所有三种降维方法中,这种分离现象都十分明显。
LLM 分类
在 t-SNE 和 UMAP 图中,我们注意到文档似乎是按照生成它们的模型进行聚类的。这让我们感到意外。Pangram 的早期版本曾有一个独立的 LLM 分类器头,但该特定任务早已被弃用。在 Pangram 3.3.2 的训练过程中,并未向其提供任何与 AI 文档源模型相对应的标签。
尽管如此,围绕原始模型家族还是形成了聚类。更有趣的是,这些聚类似乎贯穿了网络的各个层。
模型集群的形成
按模型家族对相同的嵌入结果进行着色,以便观察各层之间呈现的提供商级几何结构。
图4按模型家族着色的第2至40层嵌入。在后续层中,服务提供商级别的聚类变得更加明显。
探针
为了量化这一现象,我们针对六个模型家族(Anthropic、OpenAI、Google、Qwen、Llama、DeepSeek)训练了一个分类器,每个模型家族使用500个样本,总计3,000个样本,训练集与测试集的比例为80:20。 我们发现,仅利用全字母句(Pangram)的激活值,确实能够训练出一个探针模型,该模型能够识别特定文档所属的源模型家族,其最高Top-1准确率可达91%。
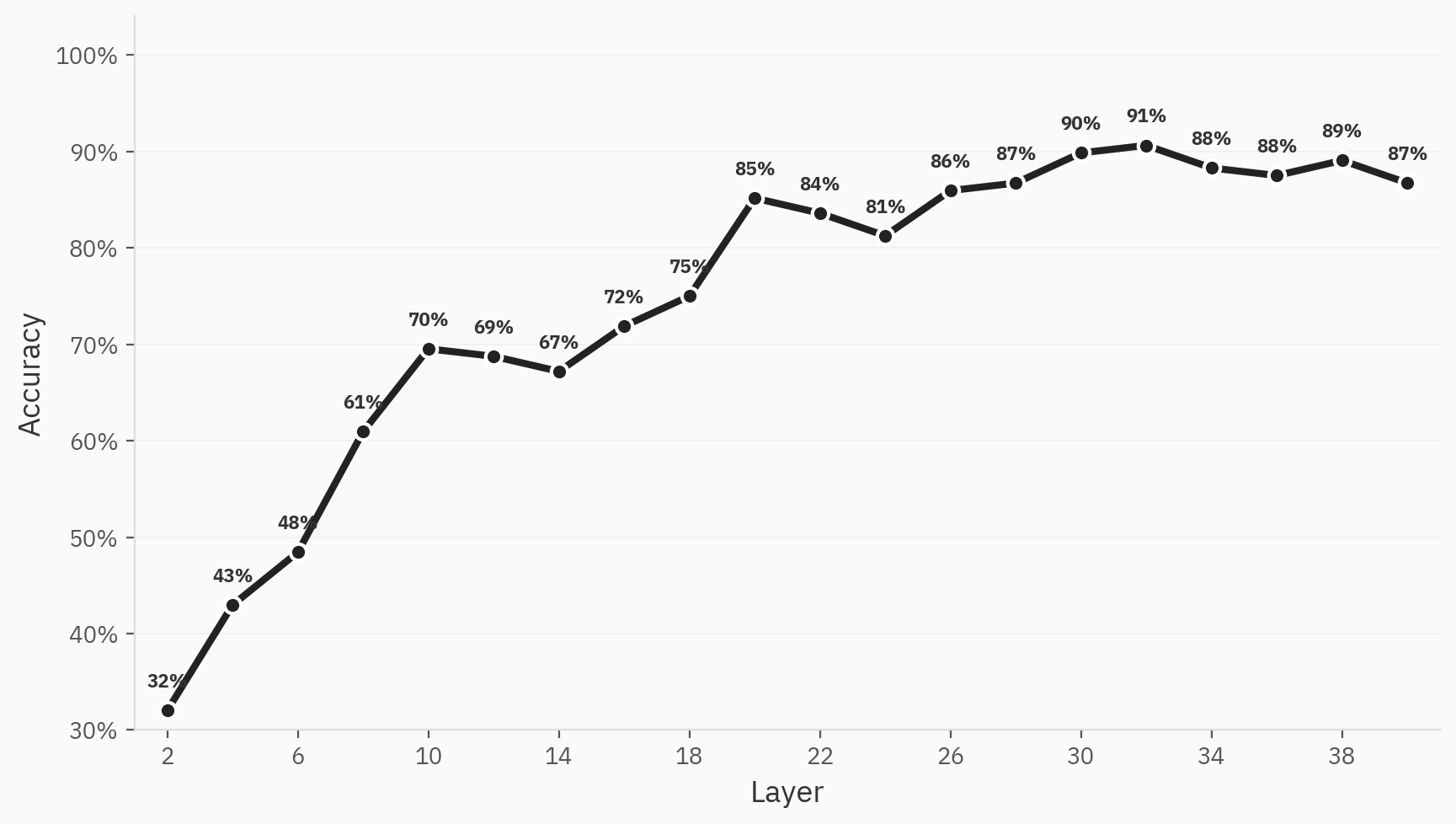
涌现并非必然
我们最初的可解释性实验涉及对多个模型的测试。出乎意料的是,“大语言模型分类”能力的出现,是该项目中各模型之间存在实质性差异的为数不多的发现之一。
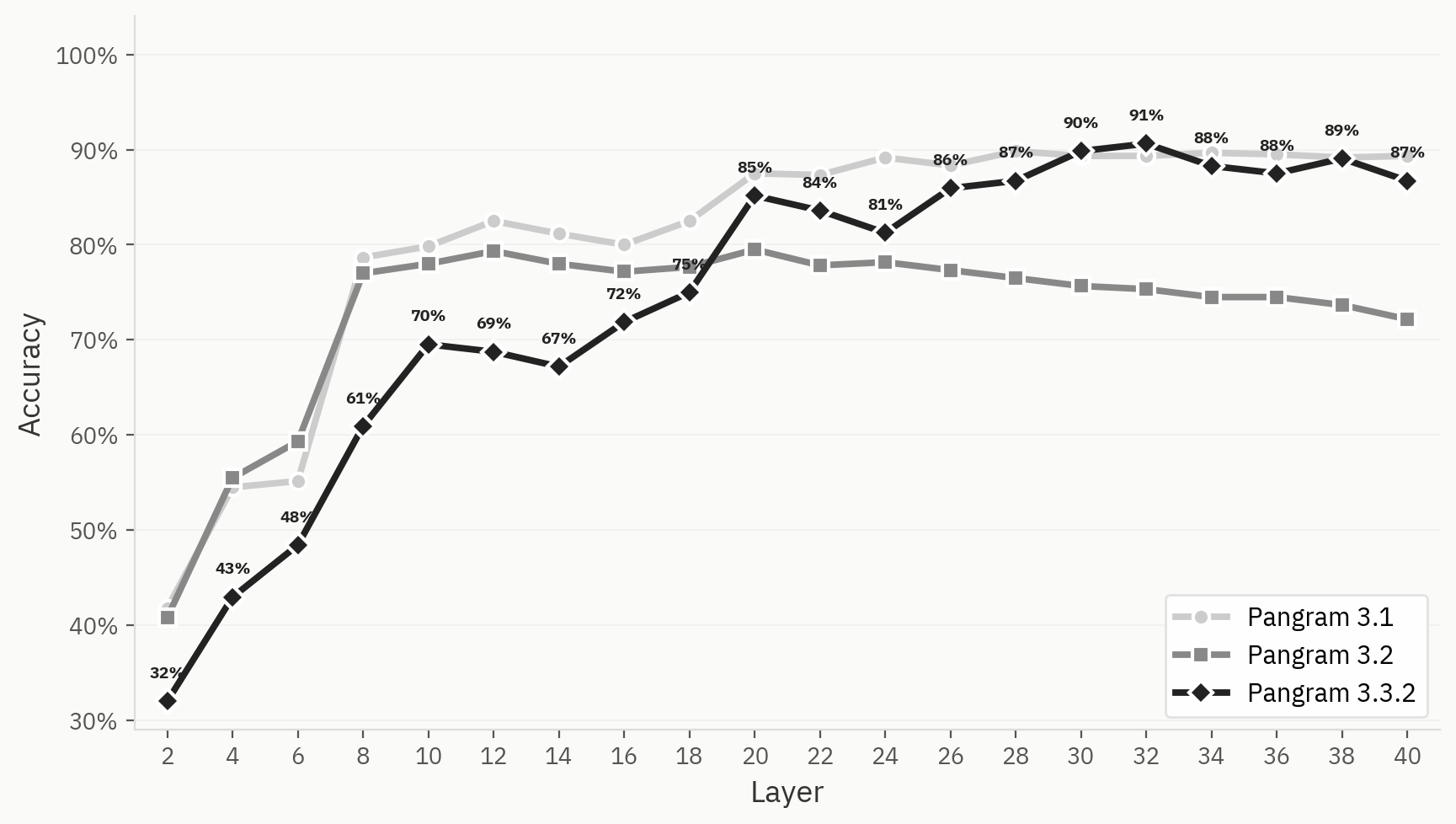
下图比较了Pangram 3.1、3.2和3.3.2的聚类表现。尽管在我们的内部最终验证中,该模型在二元人机任务上的表现优于3.1版本,但在Pangram 3.2数据集上,该模型的聚类界限总体上不如Pangram 3.1或3.3.2明确。
为了进一步说明这一差异,我们将 LLM 分类器在 Pangram 3.1、3.2 和 3.3.2 上的表现进行了比较。这三者的早期层 Top-1 准确率均有所提升,但 Pangram 3.2 的表现从第 12 层开始出现下滑,而 Pangram 3.1 和 3.3.2 则保持在较高水平。
人性化者
“Humanizers”是一类对抗性工具,旨在通过某种方式修改人工智能生成的文本,从而规避人工智能检测器。 为了观察在激活空间中,人性化文本相对于人类文本和AI文本的位置,我们创建了一个独立的人性化处理数据集,该数据集包含约1,900个样本,在三个生成模型(Claude Sonnet 4.5、Gemini 2.5 Pro 和 GPT-5)、十种不同的人性化处理服务以及与原始可解释性数据集相同的源领域之间大致保持平衡。 鉴于存在对抗性风险,我们不会披露所使用的具体服务名称。
模型如何识别“humanizers”
我们“人性化”数据集中的某些样本,确实给模型的检测带来了挑战。在此,我们采用与“人类/AI”任务相同的线性探针,只是将“人性化”文本标记为AI,这与原始训练设置一致。我们发现,即使从第一层开始,系统就始终将“人性化”文本识别为比其直接对应的AI文本更具人性化特征。
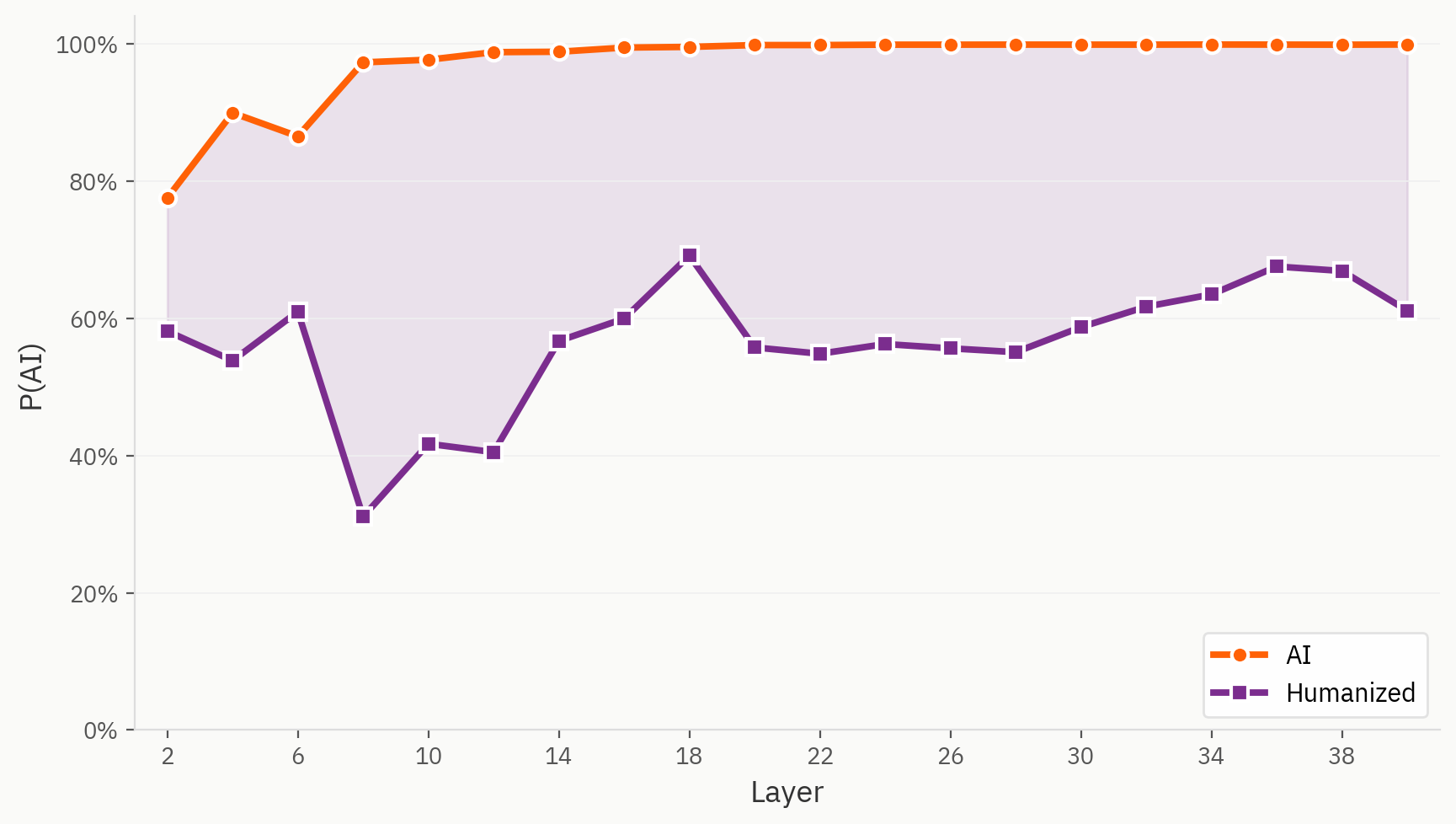
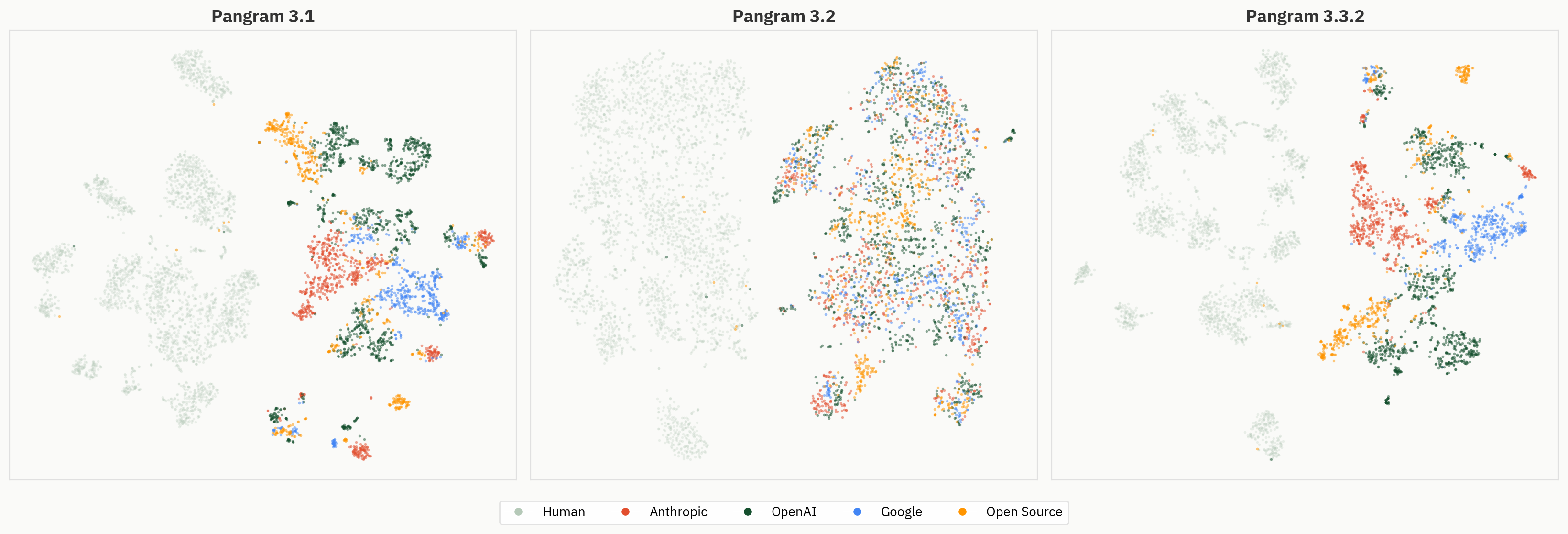
“Humanizers”在嵌入空间中的位置
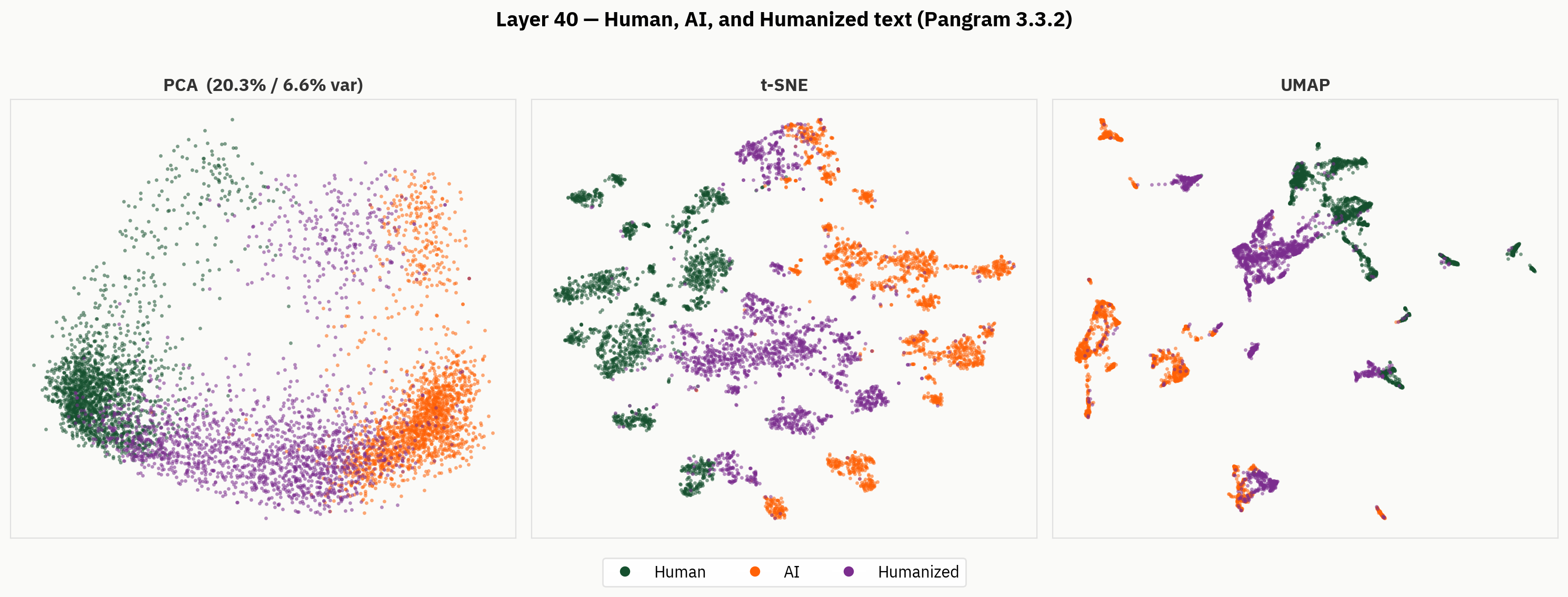
然而,当我们深入分析最终结果时,发现“人性化”文本的表征要丰富得多。下文中,我们将维度缩减方法应用于人类文本、AI文本以及“人性化”文本。从定性角度来看,我们可以观察到,“人性化”文本往往占据激活空间中的不同区域,并在人类和AI区域之外形成聚类。
我们的假设是,尽管缺乏对“人性化文本”的标签,该模型仍能够区分“人性化文本”、“人类文本”和“AI文本”。然而,在最终输出结果中,该模型被迫将这一信号合并,且合并过程并不一致。
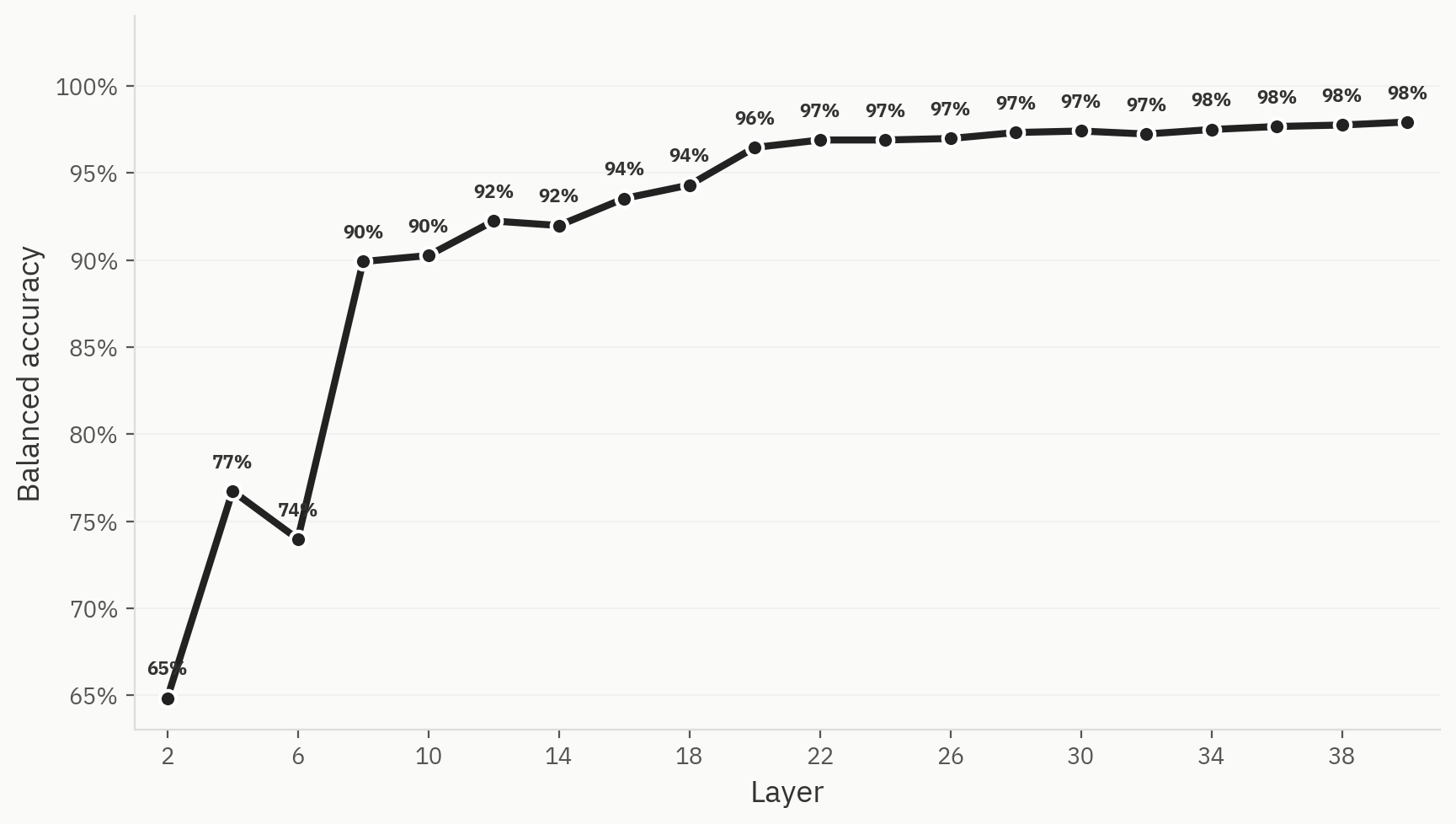
探针
为了验证这一假设,我们训练了一个三分类线性探针模型,其标签分别对应AI文本、人类文本和拟人化文本。该探针模型在网络早期就达到了较高的Top-1准确率,最终稳定在98%。
结论
我们的研究表明,Pangram 的内部表征所包含的结构,比最终的二进制输出所揭示的更为丰富。在各层之间,我们可以看到人类文档与 AI 文档相互分离,模型家族的信息逐渐显现,而拟人化文本则占据了激活空间中的独立区域。这些发现尚处于初期阶段,但它们为我们提供了一份有用的指南,有助于理解模型在将所有信息归纳为单一检测分数之前究竟学到了什么。
这篇文章仅展示了我们在可解释性方面所做的初步尝试,但在内部,我们对这一研究方向充满热情并深感兴趣。
我们对 Pangram 模型可解释性和可说明性的愿景是,它能够:
- 帮助内部人员更好地理解模型的行为。
- 请针对每个全字母句的结果提供支持性证据和更清晰的解释。
如果您是研究人员,并对可解释性、AI检测研究或本研究中的其他内容感兴趣,请联系elyas@pangram.com。
