面向机器学习与数据团队的 AI 检测
面向机器学习工程师和数据科学家的 AI 检测工具
优化大型语言模型(LLM)的训练和数据筛选。通过以99.98%的准确率和高性能API,从预训练或微调数据集中过滤合成文本,从而防止模型崩溃。
由谷歌、特斯拉和斯坦福大学的研究人员开发。经ICLR和马里兰大学验证。
filter_pipeline.py
from pangram import Pangram
# Filter synthetic data from corpus
client = Pangram(api_key="your-api-key")
clean_corpus = []
for doc in training_corpus:
result = client.predict(doc.text)
if result['fraction_ai'] < 0.3:
clean_corpus.append(doc)
print(f"Corpus: {len(clean_corpus)} clean docs")深受
等全球知名品牌信赖
等全球知名品牌信赖

















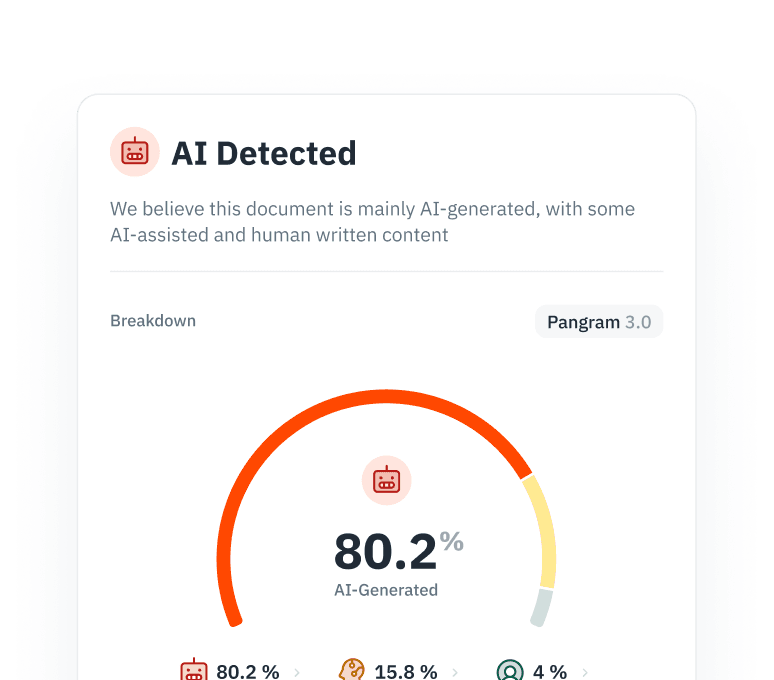
防止模型坍缩
对人工智能生成的内容进行递归训练会降低模型性能并削弱多样性。请在数据抓取流程中识别并过滤人工智能生成的内容,以确保语料库的纯净度。
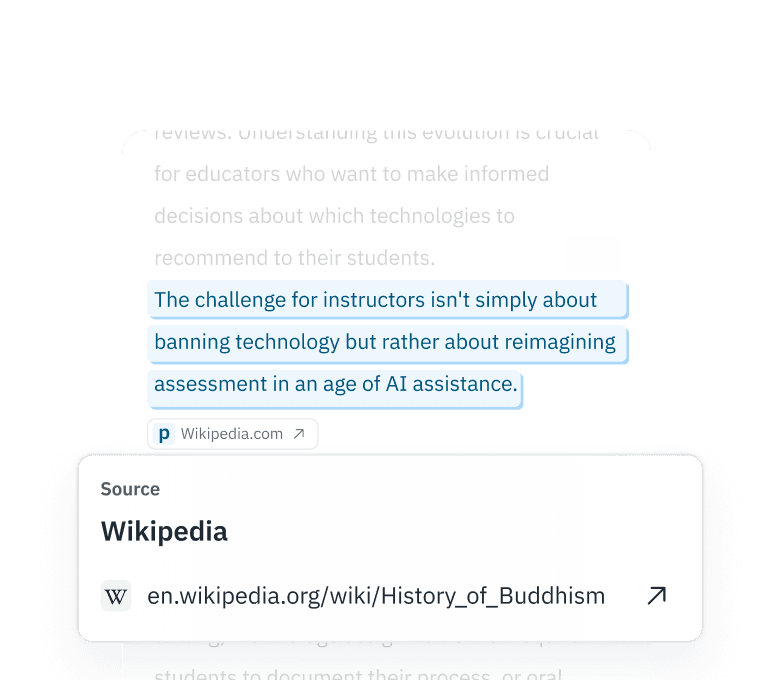
验证 RLHF 输入
确保您的人工反馈(RLHF)数据确实来自真人。检测众包工作者是否在使用ChatGPT来生成您微调任务的回答。
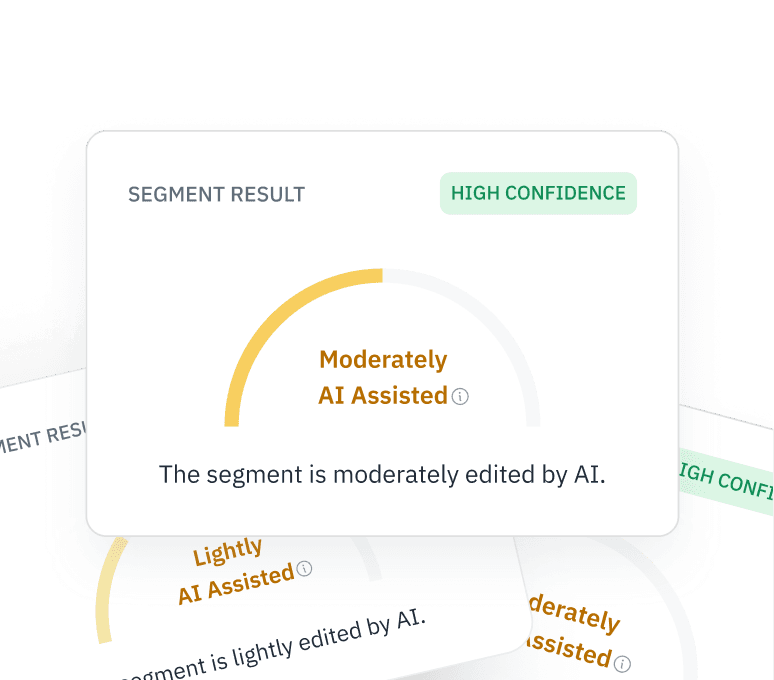
粒度可解释性
不要满足于简单的二元标签。我们的高级 API 会返回令牌级别的概率值,让您既能保留人工编辑的片段,又能剔除完全由机器生成的“垃圾内容”。

集成
专为您的
数据管道打造

03
安全与《
》合规性
已通过 SOC 2 Type 2 全面认证。我们提供专用终端节点和严格的数据保留政策——我们绝不会使用您的专有数据进行训练。
了解更多 →
我们的模型是在一个包含数百万份人类与AI文档配对的、多样化的专有数据集上训练而成的。我们利用主动学习来针对边缘案例,并特别致力于减少对非母语写作者的偏见。
该 API 返回一个预测分数(0.0 到 1.0)和一个分类标签。高级接口提供窗口级分析,用于可视化文档中的“突发性”和语法模式。
不。对于企业客户,我们提供零保留保证:数据在内存中处理,并在评分完成后立即删除,以确保隐私安全。
是的。我们会在前沿模型(如Gemini Ultra和GPT-4)发布后的几天内,立即利用其输出结果对我们的分类器进行持续再训练。
我们的模型专门针对对抗性攻击以及试图混淆合成文本的“人性化生成器”进行了训练。通过在训练过程中采用硬负样本挖掘,我们最大限度地减少了在风格上符合正式人类写作的文本中出现的误报。
是的。您可以安装pangram-sdk,仅需几行代码即可将检测功能集成到 Airflow 或 Databricks 管道中。我们的 API 专为高吞吐量的企业级抓取操作进行了优化,能够以低延迟处理数百万次请求。
与二元检测器不同,Pangram 提供词元级别的概率值。这种精细的可解释性使您能够识别并保留人工编辑的片段,同时从训练数据集中过滤掉完全合成的“垃圾”内容。
使用全字母句有助于防止模型崩溃。通过从爬取管道中过滤掉AI生成的递归内容,您可以保持语料库的纯净度,并确保模型不会因使用低质量数据进行训练而导致性能或多样性下降。
