Cet article de blog a été republié depuis le Substack de l'auteur. Suivez-le ici!
Déclaration de financement : les crédits OpenRouter nécessaires à la réalisation de cette étude ont été fournis par Pangram, et l'idée initiale de cette étude a été suggérée par Max Spero, PDG de Pangram. J'ai fait de mon mieux pour rester impartial et le texte ci-dessous reflète mes opinions sincères.
À l’époque où ChatGPT a fait son apparition, plusieurs affaires très médiatisées ont vu des personnes tenter de l’utiliser comme détecteur d’IA – c’est-à-dire en lui soumettant un texte et en lui demandant sans détour s’il avait été généré par une IA ou non. Le Washington Post a rapporté le cas d’ un professeur de l’université Texas A&M qui avait attribué des zéros à plusieurs étudiants au motif que ChatGPT revendiquait la paternité de leurs travaux. Une professeure adjointe de l’université de San Francisco a déclaré à ses collègues : « Il suffit de demander “C’est vous qui avez écrit ça ?”, puis de copier-coller le travail de l’étudiant dans la zone de saisie. » Elle a ensuite publié un article de blog dénonçant le nombre absurde de faux positifs générés par cette méthode. Plus récemment, lorsqu’un lauréat d’un concours de nouvelles organisé par Granta a été accusé d’avoir utilisé l’IA, Granta a fait appel à Claude pour déterminer si le texte primé avait effectivement été généré par l’IA.
Même si ces tentatives peuvent paraître naïves, voire un peu amusantes – après tout, ChatGPT n’a aucun moyen de vérifier qu’il a généré un texte et doit deviner en se basant sur son intuition (tout comme le ferait un humain) – Mais ce n’est pas une déduction irrationnelle pour une personne non initiée à la technique : ChatGPT peut écrire des histoires comme un auteur humain, et les auteurs humains peuvent reconnaître/se souvenir de leur œuvre, alors pourquoi pas ChatGPT ? De plus, il existe d’autres formes de vérification de la génération par IA, comme SynthID pour les images, l’audio et la vidéo. Pourquoi pas une pour le texte ? La réponse, à savoir que SynthID nécessite un filigrane détectable, n’est pas évidente. Pour ajouter à la confusion, si vous demandez à Gemini si une image est générée par l’IA, il répond simplement : « Oui, la majeure partie ou la totalité de cette image a été générée ou modifiée à l’aide de l’IA de Google. » — ce qui occulte la vérification par filigrane de SynthID et donne l’impression que Gemini peut simplement le déduire visuellement en se fiant à son intuition. Donc, pour clarifier toute cette ambiguïté :
- Les modèles de langage de grande envergure (LLM) ne disposent d'aucune mémoire épisodique de la génération d'un texte ; ils ne peuvent donc pas l'identifier du simple fait de l'avoir rédigé.
- Le tatouage numérique du texte existe bel et bien — comme le « SynthID Text » de Google —, mais il nécessite que le texte ait été généré par un système d'IA participatif sur lequel cette fonctionnalité est activée. Il ne s'agit donc pas d'une solution universelle pour n'importe quel texte.
- Ainsi, la détection de textes générés par l'IA doit s'appuyer sur l'intuition : qu'il s'agisse de l'intuition humaine, d'algorithmes d'apprentissage automatique entraînés (comme Pangram) ou de l'intuition d'un modèle de langage de grande capacité (LLM).
Et historiquement, les intuitions des grands modèles de langage (LLM) ont été médiocres ! Cela est tout à fait logique : la première génération de LLM destinés au grand public — GPT-3.5 et GPT-4, voire peut-être Claude 3 — a été formée sur des données antérieures à l’inondation de l’Internet par l’IA. Leur exposition aux textes générés par l’IA était probablement limitée, voire inexistante ; il est donc naturel que leurs performances en mode « zero-shot » soient médiocres. Mais cela soulève la question suivante : les grands modèles de langage plus modernes, entraînés sur des données plus récentes, auraient-ils peut-être une meilleure intuition ?
Adam Kucharski a mené une étude à ce sujet sur son Substack, et les premiers résultats sont prometteurs : Claude a réussi à distinguer deux débuts d’histoires générés par une IA d’un autre écrit par un humain, à identifier dix histoires rédigées par GPT-5.5 comme étant le fruit d’une IA avec une probabilité supérieure à 80 %, et n’a attribué qu’une probabilité maximale de 22 % d’être l’œuvre d’une IA à dix histoires tirées des écrits personnels de Kucharski. Plus prometteur encore, Kucharski a demandé à GPT-5.5 d’« améliorer » chacune de ses dix histoires, et cinq d’entre elles sont passées du statut d’« écrites par un humain » à celui d’« générées par une IA ». Cela représente vingt-trois succès en matière de classification directe par l’IA, et cinq succès pour cinq échecs en matière de classification de l’édition par l’IA.
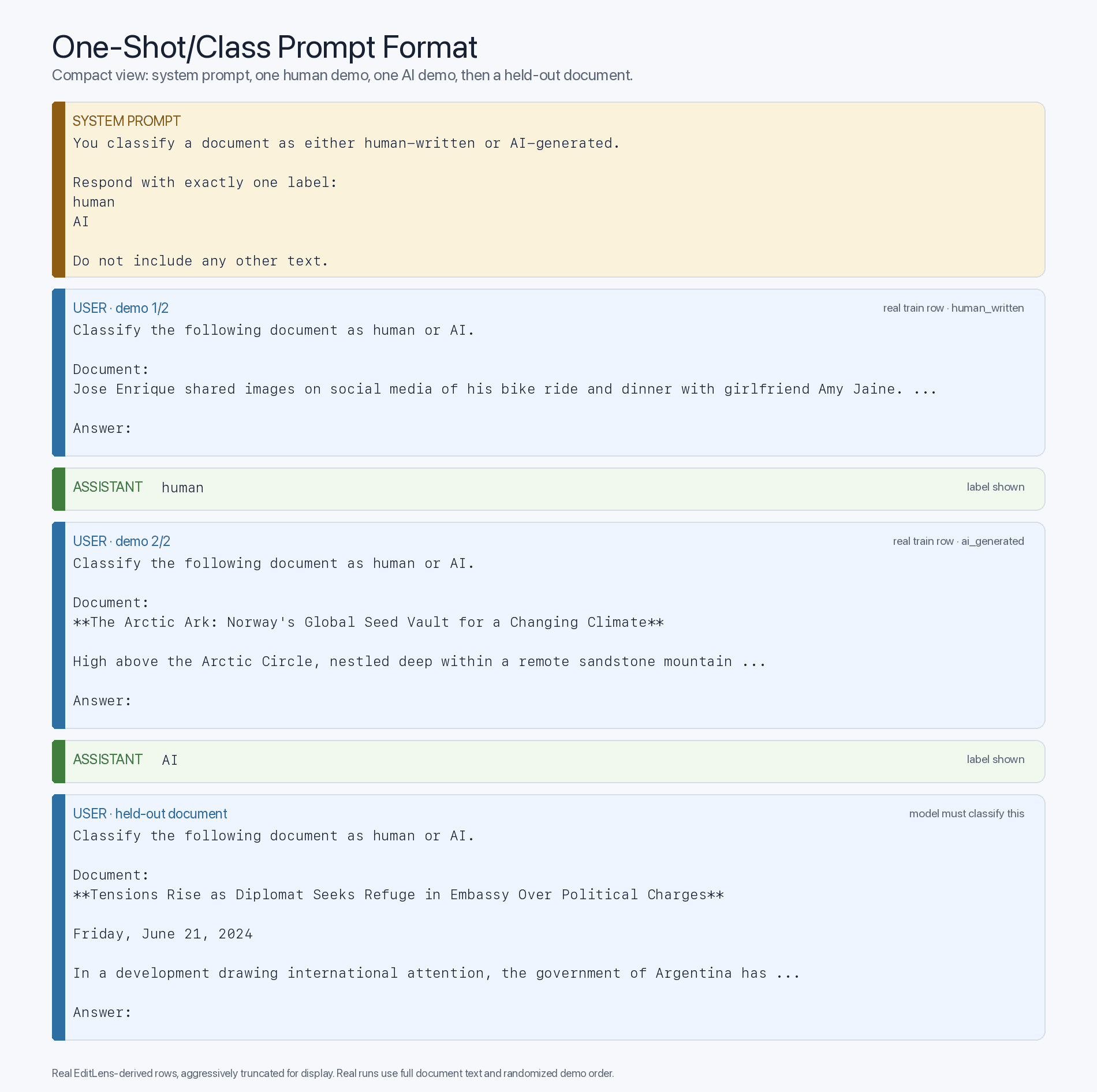
Cela soulève la question suivante : quand cette capacité de détection de l’IA est-elle apparue ? Pour tester cela, j’ai utilisé le jeu de données ouvert « editlens-iclr » de Pangram, qui contient de nombreux exemples de passages rédigés par des humains et de versions générées par l’IA de ces mêmes passages. Pour commencer, j’ai prélevé un échantillon pilote de 100 passages — 50 rédigés par des humains et 50 générés par l’IA — et j’ai évalué une série de modèles — tant historiques qu’actuels — pour déterminer leur précision en mode « zero-shot ». Afin d’optimiser la classification basée sur l’ambiance — l’intuition que je cherchais à détecter —, j’ai mené cette expérience en désactivant le raisonnement lorsque cela était possible et en donnant des instructions strictes de ne répondre qu’en un seul mot. Cela a donné lieu au format de prompt « zero-shot » suivant :
 Format de prompt « zero-shot »
Format de prompt « zero-shot »
Les résultats sont présentés ci-dessous et sont assez frappants :
 Performances « zero-shot » par date de sortie
Performances « zero-shot » par date de sortie
On constate que GPT-4 commence à 52 % — ce qui n’est pas mieux que le hasard —, ce qui correspond à l’intuition de 2023/2024 selon laquelle l’IA n’est pas capable de détecter ses propres textes (GPT-3.5-Turbo a obtenu 49 % et n’est pas inclus dans le graphique ci-dessus). Si l’on fait un bond en avant jusqu’au printemps et à l’été 2025, GPT-4.1 atteint 71 %, Sonnet 4 62 % et Opus 4 69 %. S'ensuit alors une progression rapide des capacités entre le milieu de l’été 2025 et le début de l’année 2026, période durant laquelle les séries GPT et Claude atteignent toutes deux des taux de précision supérieurs à 90 % sur cet échantillon de 100 exemples. Ce bond en avant se produit également, bien qu’un peu plus tard, pour la série Qwen Plus, dont la précision grimpe en flèche, passant de 55 % pour la version Qwen3.5 Plus à 83 % pour la version Qwen3.6 Plus, sortie seulement deux mois plus tard.
On peut se demander si cet avantage en mode « zero-shot » s’explique principalement par une familiarité avec le contenu généré par l’IA ou s’il s’agit simplement d’un écart d’intelligence — les modèles de pointe, plus performants, s’avérant être de meilleurs classificateurs. Pour vérifier cela, nous pouvons observer comment l’insertion d’exemples en mode « few-shot » (issus de l’ensemble d’entraînement et randomisés pour chaque question, bien sûr) dans le contexte modifie la précision. Cela nous amène à améliorer le format de notre prompt pour adopter le modèle « few-shot » suivant :
Si, dans ce format de prompt à quelques exemples, les anciens modèles s'améliorent considérablement lorsqu'ils sont exposés à des correspondances entrées-étiquettes appropriées, alors le goulot d'étranglement réside dans l'exposition au pré-entraînement, et non dans l'intelligence. Et c'est exactement ce que nous observons :
 Graphique ICL du GPT par question
Graphique ICL du GPT par question
Alors que GPT-4 n'obtient que 52 % en mode « zero-shot », en mode « 4-shot »1 , il atteint 85 %. Il est clair que GPT-4 est capable d’apprendre, en contexte, à distinguer les textes générés par l’IA de ceux rédigés par des humains — il lui manque simplement les connaissances innées, acquises lors du pré-entraînement, pour y parvenir. Ce constat est souligné par le fait que les performances en mode « zero-shot » s’améliorent de manière quasi monotone au fur et à mesure des générations de modèles, tandis que les performances en mode « few-shot » restent pratiquement stables après environ GPT-5.1 et ne progressent de manière notable qu’à partir de GPT-5.5, pour atteindre 99 %. Ces résultats suggèrent fortement que l’élément manquant pour que les LLM deviennent des détecteurs d’IA « zero-shot » à peu près décents était simplement des données de pré-entraînement appropriées (ou des exemples de référence en contexte), et non une quelconque contrainte intrinsèque liée à leur nature ou à leur intelligence.
Afin d’étudier plus en détail l’impact de l’apprentissage « few-shot » en contexte sur la capacité de détection de l’ICL, j’avais besoin d’un ensemble plus difficile pour extraire davantage de signaux — après tout, si les modèles de pointe actuels obtiennent un score de 95 % lors d’une évaluation sur 100 questions, cela perd tout son intérêt. Pour construire cet ensemble difficile, j’ai filtré le jeu de données Pangram afin de ne conserver que les exemples qui ont trompé Qwen 3.7 Plus à deux reprises (avec temp=0,7). J’ai ainsi obtenu 3 503 échantillons générés par IA et 763 échantillons rédigés par des humains — que j’ai ensuite équilibrés par classe (via un échantillonnage aléatoire uniforme) pour produire l’ensemble de données difficile final, composé de 763 échantillons générés par IA et de 763 échantillons rédigés par des humains.
J'évalue à la fois Sonnet 4.6 et GPT-5.5 sur cet ensemble de données complexe, avec 0, 1, 2, 4 et 8 « shots », en désactivant le raisonnement et en l'activant (niveau « effort moyen » pour GPT-5.5, et « réflexion simple étendue » pour Sonnet 4.6, pour des raisons de rapport coût-efficacité) :
 Tableau « Sonnet 4.6 » épuré
Tableau « Sonnet 4.6 » épuré
 Tableau GPT-5.5 nettoyé
Tableau GPT-5.5 nettoyé
On constate que GPT-5.5 surpasse largement Sonnet 4.6 en mode « zero-shot » — ce qui était prévisible, puisque GPT-5.5 est sorti en avril 2026 et Sonnet 4.6 en février 2026. Il est à noter que cet écart se réduit considérablement avec l’ICL : alors que (sans raisonnement) GPT-5.5 obtient un taux de 86,8 % en mode « zero-shot » contre 72,9 % pour Sonnet 4.6, avec 8 exemples, GPT-5.5 atteint 96,2 % contre 93,8 % pour Sonnet 4.6. Cela confirme une fois de plus que la détection de l’IA est, comme presque tout autre type de classification de texte, une capacité qui peut s’acquérir en fonction du contexte.
Il est à noter que, si le raisonnement entraîne une amélioration significative de quelques points de pourcentage pour le GPT-5.5, il n’aide réellement le Sonnet 4.6 que dans le régime « zero-shot » (avec un gain de +2,2 %) et n’a ensuite qu’un effet négatif ou positif à peine perceptible. Les tests statistiques le confirment : après correction de Bonferroni, le gain obtenu par GPT-5.5 grâce au raisonnement reste statistiquement significatif à 0, 1, 2 et 8 « shots », tandis que Sonnet 4.6 n’affiche un effet significatif qu’en mode « zero-shot ».
Cela semble indiquer que, même si le calcul au moment du test peut faciliter la classification de la rédaction générée par l’IA, seules certaines familles de modèles disposent de la capacité d’apprentissage nécessaire pour l’appliquer efficacement par rapport à l’intuition immédiate, et que les gains ne sont pas considérables par rapport au simple fait de fournir davantage d’exemples contextuels à partir desquels apprendre. Des travaux futurs pourraient tester GPT-5.5 à des niveaux de raisonnement « high » ou « xhigh » afin de vérifier si ces gains se maintiennent.
En résumé, nous avons constaté que les grands modèles de langage (LLM) modernes parviennent à distinguer les textes générés par l’IA de ceux rédigés par des humains, que cette capacité est probablement due à une exposition accrue aux contenus générés par l’IA lors de la pré-formation, et qu’elle bénéficie légèrement de la puissance de calcul disponible au moment du test, mais surtout d’un plus grand nombre d’exemples en contexte (au point que des LLM plus anciens comme GPT-4 peuvent l’apprendre à partir d’un niveau de référence « zero-shot » équivalent au hasard). Cela contredit l’idée reçue selon laquelle ChatGPT était incapable de déterminer si un texte avait été généré par une IA. Cependant, je ne les utiliserais toujours pas comme détecteurs d’IA dans la pratique : sur l’ensemble de données difficile, le modèle le plus performant — GPT-5.5 avec un niveau de raisonnement moyen — affiche un taux de faux positifs de 4,59 %, ce qui est inacceptable même pour une utilisation occasionnelle (à titre de comparaison, notons qu’une étude récente a révélé que le taux moyen de faux positifs de cinq annotateurs humains experts était de 5,6 %, mais qu’un ensemble de ces annotateurs affichait un FPR de 0 %). Si vous recherchez un détecteur fiable, je vous recommanderais Pangram, avec les réserves évoquées dans mon article « In Defense of Pangram ». Quoi qu’il en soit, je trouve cette capacité tout de même très intrigante — et j’ai jugé important de la documenter, étant donné que l’idée reçue ces dernières années était que les grands modèles de langage (LLM) étaient totalement incapables de détecter les textes générés par d’autres LLM. Il vaut mieux considérer que les LLM se situent globalement au niveau d’un « humain compétent à expert » en matière de détection des textes générés par l’IA. Ils sont assez précis, mais présentent des taux de faux positifs de l’ordre de quelques pour cent, ce qui rend leurs accusations inutilisables.
Notes de bas de page
-
Notez qu'ici, « 4-shot » signifie 4 exemples générés par l'IA et 4 exemples créés par des humains — et non pas 4 exemples au total. ↩

Nathan Breslow — connu sous le pseudonyme N8Programs — est étudiant en licence de mathématiques appliquées à l'université Johns Hopkins. Il travaille également sur l'apprentissage en contexte dans les grands modèles de langage (LLM) au sein de l'Intelligence Amplification Lab, contribue au développement de cadres d'inférence locaux et effectue le pré-entraînement de modèles linguistiques sur des modalités inhabituelles. Les opinions exprimées ici n'engagent que lui.
Lectures complémentaires

Comment repérer les avis générés par l'IA

L'IA écrit des œuvres de fiction primées

Comment Gradpilot utilise Pangram pour aider les étudiants à trouver leur propre style

Quel détecteur d'IA est le plus précis ? 30 outils testés (2026)
60 000 articles d'actualité générés par l'IA sont publiés chaque jour

Comment se positionne Pangram par rapport à GPTZero ?
