Table des matières
- Fiche de modèle
- À quoi s'attendre
- Quelles sont les améliorations apportées ?
- Détection des « humaniseurs » et prompts adversaires
- Détection de publications courtes sur les réseaux sociaux générées par l'IA
- Améliorations apportées à Claude 4.6
- Et maintenant ?
- Mathématiques, programmation et sciences générées par l'IA
- Poursuite de l'itération sur les Humanizers
- L'avenir
Annonce de Pangram 3.2
Mise à jour : Pangram 3.3 est désormais la dernière version disponible — découvrez les nouveautés de Pangram 3.3.
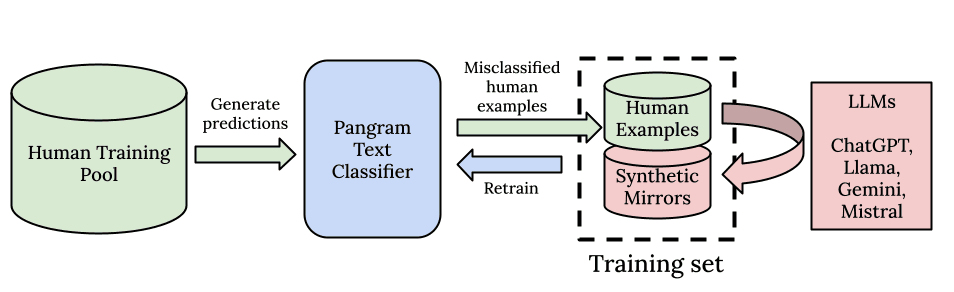
Pangram est très heureux d'annoncer la sortie d'un nouveau modèle de détection de l'IA, Pangram 3.2. À l'instar de ses prédécesseurs, Pangram 3.1 et Pangram 3.0, il repose sur l'architecture EditLens décrite dans notre article présenté à l'ICLR 2026. Nos utilisateurs peuvent s'attendre à une amélioration progressive, mais notable, du nombre de vrais positifs que le détecteur est capable de repérer (le rappel), tout en conservant le même taux de faux positifs, le plus bas du secteur, garantissant ainsi que les accusations erronées d'utilisation de l'IA restent extrêmement rares.
Fiche de modèle
Conformément aux meilleures pratiques en matière de publication de modèles de langage (LLM), nous avons décidé de commencer à publier des fiches de modèle parallèlement à nos mises à jour du détecteur : il s'agit en substance d'« étiquettes nutritionnelles » pour les modèles d'IA. Nos fiches de modèle décrivent l'architecture et le cadre d'entraînement, fournissent des détails sur l'ensemble de données d'entraînement, présentent les résultats d'évaluation pertinents et indiquent les modifications apportées susceptibles d'avoir un impact sur le comportement du détecteur. Nous décrivons également les spécifications exactes des entrées et sorties du modèle, les langues prises en charge, ainsi que les conditions dans lesquelles Pangram devrait bien fonctionner et celles où ses capacités sont plus limitées.
À quoi s'attendre
Vous remarquerez sans doute que Pangram 3.2 est plus sensible que Pangram 3.1. En d'autres termes, il détectera davantage de textes générés par l'IA. Cela s'explique par des améliorations apportées à la détection de Humanizer et de Claude 4.6, à la sensibilité de la détection des textes courts générés par l'IA, à l'ajout de données supplémentaires à l'ensemble de données d'entraînement, ainsi qu'à l'optimisation des hyperparamètres de l'architecture EditLens.
Quelles sont les améliorations apportées ?
Détection des « humaniseurs » et prompts adversaires
La principale amélioration apportée à Pangram 3.2 réside dans sa capacité à détecter les textes générés par l'IA et humanisés. Sur notre ensemble d'évaluation interne des générateurs de textes humanisés, nous avons multiplié par quatre le taux de détection par rapport à Pangram 3.1. Nous constatons également une amélioration d'environ trois fois sur notre évaluation interne des « prompts adversariaux », qui sont des textes générés par un modèle linguistique ayant reçu pour instruction d'ajouter intentionnellement des erreurs et d'écrire dans un style qui échappe à la détection par l'IA.
Cela revêt une importance particulière dans le domaine de l'éducation, où les élèves ont de plus en plus souvent recours à des outils d'humanisation ou s'efforcent de formuler leurs requêtes de manière à ce que le texte généré ne donne pas l'impression d'avoir été « trop produit par une IA ».
Détection de publications courtes sur les réseaux sociaux générées par l'IA
Compte tenu du succès fulgurant de notre bot X, que les utilisateurs ont employé pour repérer les tweets générés par l'IA, nous nous sommes récemment attachés à améliorer la détection des contenus courts, de la longueur d'un tweet, sur Internet. Nous avons également abaissé le nombre minimum de mots de 75 à 50, car nous estimons être désormais plus sûrs de notre capacité à distinguer les publications générées par l'IA comprises entre 50 et 75 mots.
Avec un taux de faux positifs équivalent à celui de Pangram 3.1, nous avons réduit de 17 % le taux de faux négatifs sur les publications courtes des réseaux sociaux dans Pangram 3.2.
Améliorations apportées à Claude 4.6
Plusieurs utilisateurs ont signalé des faux négatifs concernant spécifiquement Claude Opus 4.6. Nous avons remédié à ce problème en régénérant notre ensemble de données afin d'y inclure des données relatives à Claude Opus 4.6. Après avoir procédé à des évaluations sur nos ensembles de données de test internes (notamment sur des exemples particulièrement difficiles) et mené des tests de simulation d'attaques (red teaming), nous sommes désormais convaincus que Pangram est capable de détecter Claude Opus 4.6 aussi efficacement que n'importe quel autre modèle de langage de pointe (LLM).
Et maintenant ?
Mathématiques, programmation et sciences générées par l'IA
Le code et les calculs mathématiques générés par l'IA ne sont actuellement pas détectés avec un taux de rappel élevé. Nous nous concentrons actuellement sur ces cas d'utilisation en raison de la forte demande de nos clients. Bien que les calculs mathématiques et le code soient plus stéréotypés, et donc plus difficiles à détecter que les textes générés par l'IA, certaines de nos premières expériences donnent des résultats prometteurs.
Poursuite de l'itération sur les Humanizers
Le marché des générateurs d'images réalistes est en constante évolution, et une gamme plus large de ces outils a fait son apparition ces derniers mois. Nous développons actuellement des techniques plus avancées pour détecter ces générateurs, que nous espérons pouvoir bientôt rendre publiques.
L'avenir
Pangram s'engage à rester toujours à la pointe de ce qu'il est possible de réaliser en matière de détection par IA. Nous évoluons sans cesse, à mesure que les capacités des modèles de langage de grande envergure (LLM) ne cessent de progresser.
Nous recrutons également ! Consultez notre page Carrières pour nous aider à développer les meilleurs détecteurs d'IA au monde.

Katherine Thai est chercheuse fondatrice en intelligence artificielle chez Pangram Labs, une start-up spécialisée dans la détection par IA. Elle a obtenu son doctorat en informatique sous la direction de Mohit Iyyer à l'université du Massachusetts à Amherst en décembre 2025 ; ses travaux portaient alors sur l'évaluation des modèles de langage à grande échelle (LLM) dans le cadre de tâches liées à l'analyse littéraire.
Lectures complémentaires

Pangram détecte-t-il Llama 4 de Meta ?

Quels sont les résultats de Pangram sur les outils d'humanisation ? (Mise à jour : août 2025)

Guide de migration de l'API Pangram 3.0
Rapport technique sur la détection de textes générés par l'IA avec une grande précision

Comment repérer l'IA dans Google Docs

L'engagement de Pangram en matière de protection des données
