İçindekiler
- Model Kartı
- Neler Beklenebilir
- Neler İyileştirildi
- İnsani Özellik Algılama ve Karşıt Teşvik
- Yapay Zeka Tarafından Oluşturulan Kısa Sosyal Medya Gönderilerinin Tespiti
- Claude 4.6'daki İyileştirmeler
- Sırada Ne Var?
- Yapay zeka tarafından üretilen matematik, kodlama ve fen
- İnsanlaştırıcılar Üzerine Devam Eden Çalışmalar
- Gelecek
Pangram 3.2'nin Duyurusu
Güncelleme: Pangram 3.3 artık en son sürümdür — Pangram 3.3'teki yeniliklere göz atın.
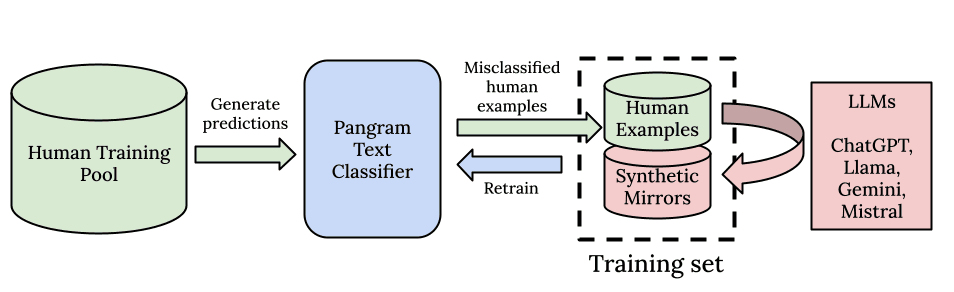
Pangram, yeni bir yapay zeka algılama modeli olan Pangram 3.2’yi piyasaya sürmekten büyük heyecan duyuyor. Önceki sürümleri Pangram 3.1 ve Pangram 3.0 gibi, bu model de ICLR 2026 bildirimizde açıklanan EditLens mimarisine dayanmaktadır. Kullanıcılarımız, dedektörün yakalayabildiği doğru pozitiflerin sayısında (geri çağırma) kademeli ancak fark edilebilir bir iyileşme bekleyebilirler. Aynı zamanda, sektördeki en düşük yanlış pozitif oranı korunarak, AI kullanımıyla ilgili yanlış suçlamaların son derece nadir kalması sağlanmaktadır.
Model Kartı
LLM sürümlerindeki en iyi uygulamaları benimseyerek, dedektör güncellemelerimizle birlikte Model Kartları yayınlamaya karar verdik: bunlar, temelde AI modelleri için birer "besin etiketi" niteliğindedir. Model kartlarımızda, eğitim mimarisi ve çerçevesi, eğitim veri kümesiyle ilgili ayrıntılar, ilgili değerlendirme sonuçları ve dedektörün davranışını etkileyebilecek değişiklikler açıklanmaktadır. Ayrıca, modelin girdi ve çıktılarının kesin özelliklerini, desteklenen dilleri ve Pangram'ın iyi performans göstermesini beklediğimiz koşulları ve daha sınırlı olduğu durumları da açıklıyoruz.
Neler Beklenebilir
Muhtemelen Pangram 3.2'nin Pangram 3.1'den daha hassas olduğunu fark edeceksiniz. Başka bir deyişle, daha fazla yapay zeka metni tespit edilecektir. Bu durum, humanizer algılamasındaki iyileştirmeler, Claude 4.6'nın algılanması, yapay zeka tarafından üretilen daha kısa metinlerin algılanmasındaki hassasiyet, eğitim veri kümesine daha fazla verinin eklenmesi ve EditLens mimarisindeki daha optimal hiperparametreler sayesinde gerçekleşmiştir.
Neler İyileştirildi
İnsani Özellik Algılama ve Karşıt Teşvik
Pangram 3.2’deki en büyük gelişme, insan tarafından yazılmış gibi görünen yapay zeka tarafından üretilmiş metinleri tespit etme yeteneğidir. Dahili insanlaştırıcı değerlendirme setimizde, insanlaştırıcıların algılama oranını Pangram 3.1'e kıyasla 4 kat artırdık. Ayrıca, kasıtlı olarak hata eklemesi ve yapay zeka algılamasından kaçınacak bir üslupta yazması talimatı verilen bir dil modeli tarafından üretilen metinler olan "karşıt komutlar"ın dahili değerlendirmesinde yaklaşık 3 katlık bir iyileşme gözlemledik.
Bu durum, öğrencilerin giderek daha fazla insanlaştırma araçları kullandığı veya ortaya çıkan metnin "fazla yapay zeka tarafından üretilmiş" gibi görünmemesi için dil modellerini yönlendirmeye çalıştığı eğitim alanında özellikle önemlidir.
Yapay Zeka Tarafından Oluşturulan Kısa Sosyal Medya Gönderilerinin Tespiti
Kullanıcıların tweetlerdeki yapay zeka tarafından üretilmiş metinleri kontrol etmek için kullandıkları X botumuzun büyük ilgi görmesi nedeniyle, son dönemde çevrimiçi ortamdaki tweet uzunluğundaki kısa içeriklerin tespitini iyileştirmeye yoğun bir şekilde odaklandık. Ayrıca, 50-75 kelime aralığındaki yapay zeka tarafından üretilmiş gönderileri ayırt etme becerimize olan güvenimiz arttığı için, minimum kelime sayısını 75'ten 50'ye düşürdük.
Pangram 3.1 ile aynı yanlış pozitif oranında, Pangram 3.2'de kısa sosyal medya gönderilerindeki yanlış negatif oranını %17 oranında iyileştirdik.
Claude 4.6'daki İyileştirmeler
Özellikle Claude Opus 4.6 ile ilgili olarak birçok kullanıcı yanlış negatif sonuçlar bildirdi. Bu sorunu, veri setimizi Claude Opus 4.6 verilerini de içerecek şekilde yeniden oluşturarak çözdük. Dahili test veri setlerimizde (özellikle zor örnekler üzerinde) yaptığımız değerlendirmeler ve kırmızı takım testlerinin ardından, Pangram’ın Claude Opus 4.6’yı diğer tüm öncü büyük dil modelleri kadar başarılı bir şekilde tespit edebileceğinden artık eminiz.
Sırada Ne Var?
Yapay zeka tarafından üretilen matematik, kodlama ve fen
Şu anda yapay zeka tarafından üretilen kod ve matematik metinleri yüksek bir tespit oranıyla algılanmamaktadır. Müşterilerimizden gelen yoğun talep nedeniyle şu anda bu kullanım senaryolarına odaklanıyoruz. Matematik ve kod metinleri daha kalıplaşmış olduğundan yapay zeka tarafından üretilen metinlere kıyasla algılanması daha zor olsa da, ilk denemelerimiz umut verici sonuçlar vermektedir.
İnsanlaştırıcılar Üzerine Devam Eden Çalışmalar
İnsancı pazarı sürekli gelişiyor ve son aylarda pazara çok daha geniş bir yelpazede insancılar girmiştir. İnsancıları tespit etmek için daha gelişmiş teknikler geliştiriyoruz ve bunları yakında kamuoyuyla paylaşmayı umuyoruz.
Gelecek
Pangram, yapay zeka tabanlı algılama alanında mümkün olanın sınırlarını her zaman zorlamaya kararlıdır. Büyük dil modellerinin (LLM) yetenekleri gelişmeye devam ettikçe, biz de sürekli olarak kendimizi geliştiriyoruz.
Ayrıca yeni çalışanlar arıyoruz! Dünyanın en iyi yapay zeka algılayıcılarını geliştirmemize yardımcı olmak için kariyer sayfamızı inceleyin.

Katherine Thai, yapay zeka tabanlı tespit alanında faaliyet gösteren bir girişim olan Pangram Labs’ın kurucu yapay zeka araştırma bilim insanıdır. Aralık 2025’te Massachusetts Amherst Üniversitesi’nde Mohit Iyyer’in danışmanlığında Bilgisayar Bilimleri alanında doktora derecesini tamamlamıştır; buradaki çalışmaları, edebi analizle ilgili görevlerde büyük dil modellerinin (LLM’ler) değerlendirilmesine odaklanmıştı.
İlgili makaleler

Pangram, Meta'nın Llama 4'ünü algılıyor mu?

Pangram, insanlaştırıcılar üzerinde ne kadar başarılı? (Ağustos 2025'te güncellenmiştir)

Pangram 3.0 API Geçiş Kılavuzu
Yüksek Hassasiyetli Yapay Zeka Tarafından Oluşturulan Metin Algılama Konusunda Teknik Rapor

Google Dokümanlar'da yapay zekayı nasıl tespit edebilirim?

Pangram'ın Veri Gizliliğine Olan Taahhüdü
adresinden güncellemelerimize abone olun
