这篇博文转载自作者的 Substack 账号。点击此处关注他!
资金披露:Pangram 为开展本研究提供了 OpenRouter 积分,且本研究的最初构想由 Pangram 首席执行官 Max Spero 提出。我已尽力保持中立,下文所述内容反映了我本人的真实观点。
早在ChatGPT刚推出时,就曾发生过几起备受瞩目的事件:有人试图将其用作AI检测工具——即向其输入一段文本,并直截了当地询问该文本是否由AI生成。 《华盛顿邮报》曾报道过德克萨斯农工大学的一位教授,他以ChatGPT声称是论文作者为由,给多名学生打了零分。旧金山大学的一位助理教授曾告诉同事:“我们只需问一句‘这是你写的吗?’,然后将学生的作业复制粘贴到提示框中。”——结果她随后写了一篇博客文章,指出这种做法产生的误报数量多得离谱。 更近期的例子是,当《格兰塔》杂志(Granta)举办的一场短篇小说比赛获奖者被指控使用AI时,该杂志便启用Claude来调查获奖作品是否确实由AI生成。
虽然这些尝试看起来可能有些天真,甚至有点滑稽——毕竟,ChatGPT 无法验证自己是否生成了某段文本,只能根据“感觉”来猜测(就像人类一样)。 但对于非技术人员来说,这种推论并非毫无道理:ChatGPT能像人类作家一样创作故事,而人类作家能够识别并记住自己的作品,那么ChatGPT为什么不能呢?此外,目前还存在其他形式的人工智能生成内容验证技术,例如用于图像、音频和视频的SynthID。为什么没有针对文本的呢?答案是SynthID需要可检测的水印,这一点并不显而易见。 更令人困惑的是,如果你问Gemini一张图片是否由AI生成,它只会回答:“是的,这张图片的大部分或全部内容都是使用Google AI生成的或编辑的。”——这掩盖了SynthID水印验证的存在,给人一种印象,即Gemini仅凭视觉上的“感觉”就能推断出来。因此,为了澄清所有这些模糊之处:
- 大型语言模型(LLMs)对生成某段文本没有情景记忆,因此无法仅凭自己写过该文本这一事实来识别它。
- 文本水印技术确实存在——例如谷歌的SynthID Text——但要求文本必须由启用了水印功能的参与式AI系统生成。因此,它并非适用于任意文本的通用解决方案。
- 因此,AI文本检测必须依靠直觉来完成——无论是人类的直觉、经过训练的机器学习算法(如Pangram),还是大型语言模型(LLM)的直觉。
而且从历史上看,大型语言模型(LLM)的直觉一直很差!这完全合乎情理——最早一批面向消费者的LLM——GPT-3.5、GPT-4,或许还有Claude 3——都是在互联网尚未被AI内容泛滥之前的数据上训练的。它们接触到的人工智能生成的文本要么几乎为零,要么非常有限,因此它们的零样本性能自然会很差。 但这引发了一个问题:那些基于更近期数据训练的现代大语言模型,是否会拥有更好的直觉呢?
亚当·库查尔斯基(Adam Kucharski)在他的Substack上对此进行了研究,初步结果令人鼓舞:Claude能够从两个AI生成的故事开头中辨别出一个由人类撰写的故事开头,以超过80%的概率识别出十篇由GPT-5.5撰写的故事为AI生成,并对从库查尔斯基个人作品中抽样的十篇故事,判定其为AI生成的概率不超过22%。 更令人鼓舞的是,库查尔斯基要求GPT-5.5“改进”他那十篇故事中的每一篇,并将其中五篇从人类创作的版本“翻转”为AI生成的版本。这意味着在直接AI分类任务中取得了二十三次成功,而在AI编辑分类任务中则取得了五次成功和五次失败。
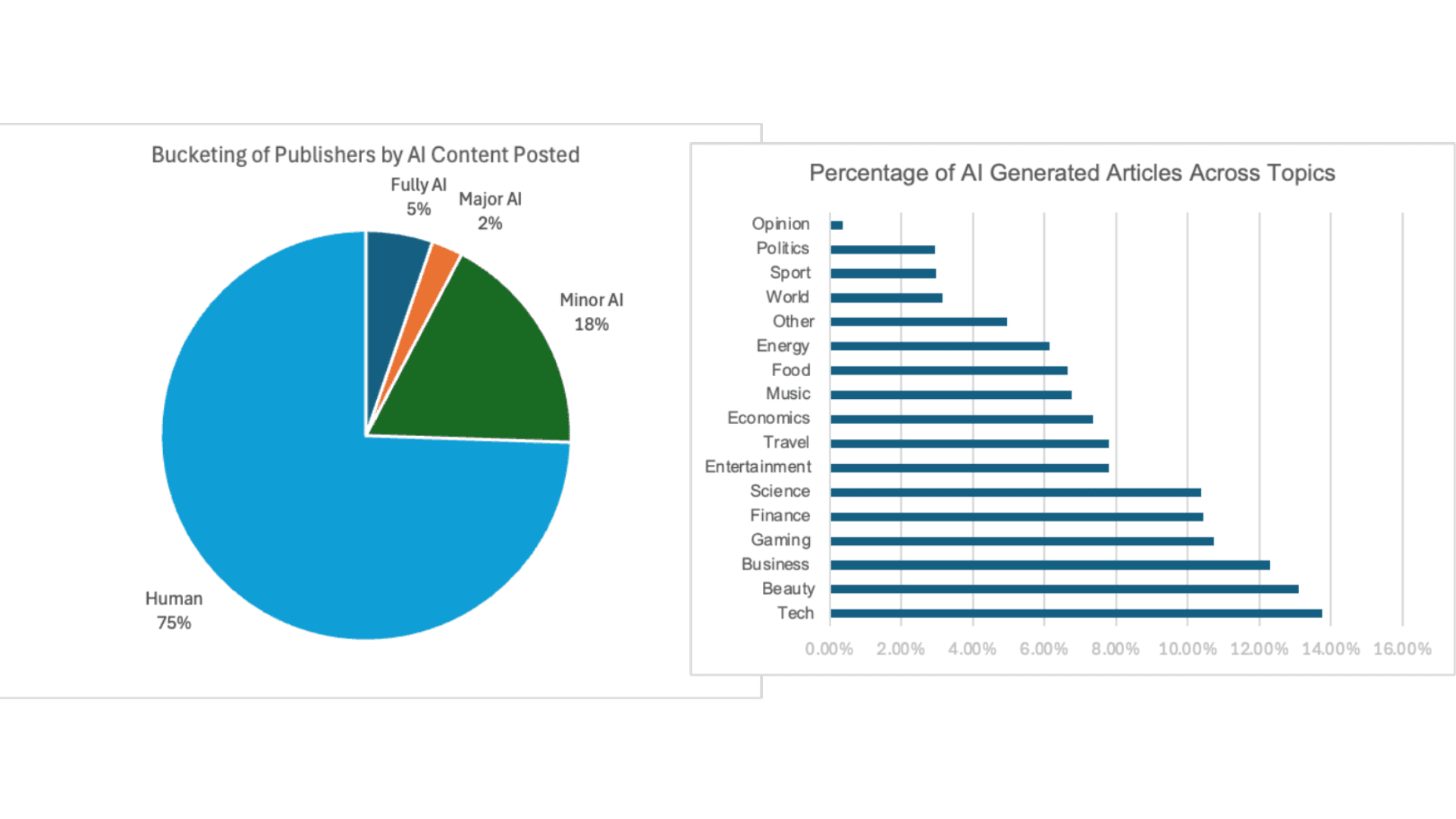
这引发了一个问题:这种AI检测能力究竟何时出现的?为了验证这一点,我使用了Pangram的开源editlens-iclr数据集,其中包含了大量由人类撰写的段落及其由AI生成的对应版本。首先,我抽取了100个段落作为试点样本——其中50个由人类撰写,50个由AI生成——并针对一系列历史和当前模型进行了零样本准确率的评估。 为了最大限度地发挥基于“氛围”的分类效果——这也是我试图探知的直觉——我在实验中关闭了可用的推理功能,并严格要求仅用一个词作答。由此得出了以下零样本提示格式:
 零样本提示格式
零样本提示格式
结果如下所示,相当引人注目:
 按发布日期划分的零样本性能
按发布日期划分的零样本性能
我们可以看到,GPT-4的初始准确率为52%——这与随机猜测无异——这与2023/2024年“AI无法识别自身生成内容”的普遍认知相符(GPT-3.5-Turbo的准确率为49%,未包含在上述图表中)。 快进到2025年春夏,GPT-4.1的准确率达到71%,Sonnet 4为62%,Opus 4为69%。 随后,从2025年仲夏到2026年初,其能力呈现出快速攀升的态势——GPT系列和Claude系列在这100个示例样本上的准确率均突破了90%。 Qwen Plus系列也出现了类似的飞跃,尽管时间稍晚一些:其准确率从Qwen3.5 Plus版本的55%飙升至仅两个月后发布的Qwen3.6 Plus版本的83%。
人们可能会疑惑,这种零样本优势主要是源于对AI生成内容的熟悉,还是单纯源于智能水平的差距——即更智能的前沿模型能作为更好的分类器。为了验证这一点,我们可以观察在上下文中插入少量样本(当然,这些样本取自训练集,并按问题随机分配)后,准确率会发生怎样的变化。这将使我们的提示格式升级为以下少量样本模板:
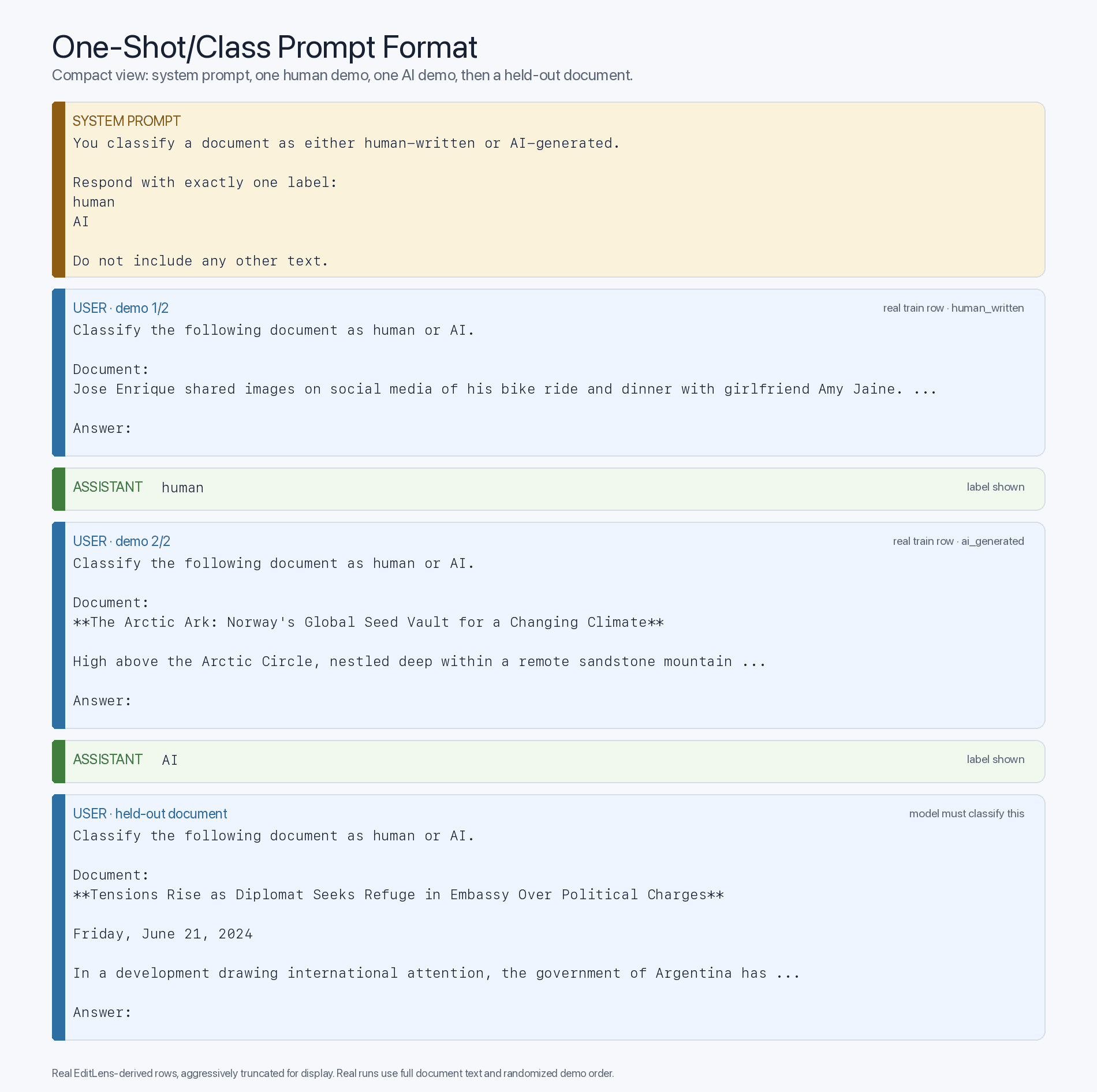
如果在这种“少量样本”提示格式下,旧模型在接触到正确的输入-标签映射后能显著提升性能,那么瓶颈在于预训练的接触程度,而非智能水平。而这正是我们所观察到的:
 GPT 按问题划分的 ICL 图表
GPT 按问题划分的 ICL 图表
虽然GPT-4在零样本任务中仅获得52%,但在4样本任务中1 其准确率则达到85%。 显然,GPT-4能够通过上下文学习来区分AI生成的文本和人类撰写的文本——它只是缺乏关于如何区分的先验预训练知识。这一点从以下现象中得到了印证:零样本性能随着模型代数的提升几乎呈单调递增趋势,但少样本性能在~GPT-5.1之后基本保持平稳,直到GPT-5.5才明显提升至99%。 这一证据有力地表明,大型语言模型(LLMs)要成为还算像样的零样本AI检测器,所缺失的关键因素仅仅是合适的预训练数据(或黄金上下文示例),而非其本质或智能上的任何内在限制。
为了进一步研究少样本上下文学习对ICL检测能力的影响,我需要一套更具挑战性的数据集来提取更多有效信息——毕竟,如果现代前沿模型在100道题的评估中能达到95%的准确率,那么该方法就失去了意义。为了构建这套高难度数据集,我对Pangram数据集进行了筛选,仅保留那些曾两次(在temp=0.7条件下)误导Qwen 3.7 Plus的示例。 这为我提供了3,503个AI生成的样本和763个人工撰写的样本——随后,我通过均匀随机采样对样本进行了类别平衡,最终生成包含763个AI生成的样本和763个人工撰写的样本的“高难度”数据集。
我使用该高难度数据集对 Sonnet 4.6 和 GPT-5.5 进行了评估,分别在 0、1、2、4 和 8 次提示下,分别测试了关闭推理和开启推理的情况(出于成本效益考虑,GPT-5.5 采用“中等努力”模式,Sonnet 4.6 采用“简单扩展思考”模式):
 整理后的《十四行诗》第4.6首图表
整理后的《十四行诗》第4.6首图表
 清理后的 GPT-5.5 图表
清理后的 GPT-5.5 图表
我们可以看到,GPT-5.5 在零样本任务上的表现远超 Sonnet 4.6——这在意料之中,因为 GPT-5.5 发布于 2026 年 4 月,而 Sonnet 4.6 发布于 2026 年 2 月。 值得注意的是,在采用ICL的情况下,这一差距大幅缩小——虽然(在关闭推理功能时)GPT-5.5的零样本准确率为86.8%,而Sonnet 4.6为72.9%;但在8次测试中,GPT-5.5的准确率达到96.2%,而Sonnet 4.6为93.8%。 这进一步印证了:与几乎所有其他类型的文本分类一样,许多AI检测能力都是在特定语境下才能体现的。
值得注意的是,虽然推理能力使 GPT-5.5 的表现显著提升了几个百分点,但它实际上仅在零样本学习场景下对 Sonnet 4.6 有所帮助(提升 2.2%),而在该场景之后,其影响要么微乎其微,要么几乎没有。 统计检验证实了这一点——经过邦费罗尼校正后,GPT-5.5从推理中获得的收益在0、1、2和8次训练中仍具有统计学意义,而Sonnet 4.6仅在零次训练时才具有显著效果。
这似乎表明,虽然测试时的计算能力有助于AI写作分类,但只有部分模型家族具备相应的训练基础和能力,能够将其有效应用于即时直觉,而且与单纯提供更多上下文示例供模型学习相比,这种方法带来的收益并不显著。未来的研究可以测试GPT-5.5在“高”或“x高”推理水平下的表现,以观察收益是否依然存在。
总而言之,我们看到现代大型语言模型(LLMs)能够成功区分AI生成的文本与人类撰写的文本;这种能力很可能源于预训练阶段接触了更多AI生成的内容;此外,虽然测试阶段的计算资源能带来些许帮助,但更多上下文示例的作用更为显著(甚至到了像GPT-4这样的较旧LLMs也能从零样本随机水平基线中学会这种能力的地步)。 这与此前“ChatGPT无法判断一段文本是否由AI生成”的说法相悖。不过,在实际应用中,我仍然不会将它们用作AI检测器——在困难数据集上,表现最佳的模型 ——即启用中等推理能力的 GPT-5.5,其假阳性率仍高达4.59%,这一数值即使对于非专业用途也难以接受(作为参考,近期一项研究发现,五位专家标注员的平均假阳性率为 5.6%,但由这些标注员组成的集成模型假阳性率为 0%)。 如果你正在寻找一个可靠的检测器,我推荐 Pangram,但需注意我在《为 Pangram 辩护》一文中讨论过的注意事项。 尽管如此,我仍然认为这种能力非常引人入胜——而且我认为有必要记录下来,因为过去几年的普遍共识是,大型语言模型(LLM)完全无法检测出由 LLM 生成的文本。相反,将 LLM 在检测 AI 生成的文本方面的能力大致建模为“良好至专家级人类”水平更为恰当。它们的准确率相当高,但存在单个百分点的假阳性率,这使得其检测结果无法付诸行动。
脚注
-
请注意,此处的“4-shot”指的是4个AI示例和4个人类示例,而不是总共4个示例。↩

内森·布雷斯洛(Nathan Breslow)——网名 N8Programs——是约翰斯·霍普金斯大学应用数学专业的本科生。此外,他还曾在“智能增强实验室”(Intelligence Amplification Lab)从事大型语言模型(LLMs)的上下文学习研究,为本地推理框架做出贡献,并利用非传统模态对语言模型进行预训练。本文观点仅代表其个人立场。