このブログ記事は、著者のSubstackから転載したものです。こちらから彼をフォローしてください!
資金提供に関する開示:本研究の実施にあたり、Pangram社よりOpenRouterのクレジットが提供されました。また、本研究の当初のアイデアは、Pangram社のCEOであるMax Spero氏から提案されたものです。私は公平性を保つよう最善を尽くしており、以下の文章は私の率直な見解を反映したものです。
ChatGPTが初めて登場した当時、これをAI検出ツールとして使おうとしたという注目すべき事例がいくつかありました。つまり、テキストを入力し、それがAIによって生成されたものかどうかを率直に尋ねたのです。 ワシントン・ポスト紙は、ChatGPTが学生の論文の著作者であると主張したことを理由に、テキサスA&M大学の教授が複数の学生に0点をつけた事例を報じました。サンフランシスコ大学の助教授は同僚に対し、「『これを書いたのはあなたですか?』と尋ね、学生の作品をプロンプトボックスにコピー&ペーストするだけでいい」と語りましたが、その後、この方法によって途方もない数の誤検知が発生したことをブログ記事に綴りました。 さらに最近では、グランタ誌が主催する短編小説コンクールの受賞者がAIの使用を疑われた際、グランタ誌は「クロード」を用いて、受賞作が実際にAIによって生成されたものかどうかを調査した。
こうした試みは、素朴で、おそらく少し滑稽に思えるかもしれません――何しろ、ChatGPTには自分がテキストを生成したことを確認する手段がなく、(人間と同じように)雰囲気から推測するしかないのですから。 しかし、技術に詳しくない人にとって、これは決して不合理な推論ではありません。ChatGPTは人間の作家のように物語を書くことができ、人間の作家は自分の作品を認識・記憶できるのですから、ChatGPTにもそれができないはずがないでしょう?さらに、画像、音声、動画向けのSynthIDのような、AI生成の検証手段は他にも存在します。テキスト向けのものがあってもおかしくないはずです。その答えとして、「SynthIDには検出可能な透かしが必要だ」という点は、一見して明らかではありません。 さらに混乱を招くのは、Geminiに「この画像はAI生成か」と尋ねると、単に「はい、この画像の大部分またはすべてがGoogle AIを使用して生成または編集されました」と答える点だ。これにより、SynthIDによる透かし検証が隠蔽され、Geminiが視覚的な「雰囲気」だけでAI生成であると推測できるかのような印象を与えてしまう。そこで、こうした曖昧さをすべて明確にするために:
- LLMには、あるテキストを生成したというエピソード記憶がないため、自分が書いたという事実だけでそのテキストを特定することはできない。
- テキストへの透かし入れ技術は確かに存在します(Googleの「SynthID Text」など)。しかし、これを利用するには、透かし機能が有効になっている参加型AIシステムによってテキストが生成されている必要があります。したがって、任意のテキストに対して普遍的に適用できる解決策というわけではありません。
- したがって、AIによるテキスト検出は、直感に基づいて行わなければならない。その直感とは、人間の直感、学習済みの機械学習アルゴリズム(Pangramなど)、あるいはLLMの直感のいずれかである。
そして歴史的に見ても、LLMの直感的な判断は不正確でした!これは極めて理にかなっています。一般消費者向けの初期世代のLLM――GPT-3.5やGPT-4、おそらくClaude 3も――は、いずれもインターネットがAIによって汚染される前のデータで学習されたものです。AI生成テキストへの接触は、皆無ではないにせよ限られていたため、当然ながらゼロショット性能は低かったのです。 しかし、ここで疑問が生じます。より新しいデータで学習された、より現代的なLLMは――もしかすると、より優れた直感を持っているのではないでしょうか?
アダム・クチャースキー氏は自身のSubstackでこの件について調査を行い、初期の結果は有望なものとなっています。Claudeは、AIが生成した2つの物語の冒頭部分と、人間が書いた1つの冒頭部分を区別することができ、GPT-5.5が書いた10の物語を80%以上の確率でAI生成と特定し、クチャースキー氏の個人的な執筆作品から抽出した10の物語については、AI生成である確率を22%以下と判定しました。 さらに有望なことに、クチャースキー氏はGPT-5.5に対し、自身の10編の物語それぞれを「改善」するよう依頼し、そのうち5編は人間が書いたものからAI生成のものへと入れ替えました。これにより、AIによる直接分類では23件の成功、AIによる編集の分類では5件の成功と5件の失敗という結果となりました。
そこで疑問が生じます。このAI検出能力はいつから現れたのでしょうか?これを検証するために、私はPangramのオープンデータセット「editlens-iclr」を使用しました。このデータセットには、人間が作成した文章と、それと同じ文章をAIが生成した「ミラーテキスト」の豊富な例が含まれています。まず、100件の文章(人間作成50件、AI生成50件)をパイロットサンプルとして抽出し、過去および現在のさまざまなモデルについて、ゼロショット精度を評価しました。 私が検知しようとしていた直感、すなわち「雰囲気」に基づく分類を最大限に引き出すため、可能な場合は推論機能をオフにし、回答は1語のみに限定するという厳格な指示の下でこの実験を実施しました。その結果、以下のゼロショット・プロンプト形式が導き出されました:
 ゼロショット・プロンプト形式
ゼロショット・プロンプト形式
その結果を以下に示しますが、その内容は実に印象的です:
 リリース日別のゼロショット性能
リリース日別のゼロショット性能
GPT-4の正答率は52%から始まっており、これは偶然の確率と変わらない水準であり、2023/2024年当時の「AIには自身の文章を識別する能力がない」という通説と一致している(GPT-3.5-Turboは49%だったが、上記のグラフには含まれていない)。 2025年の春から夏にかけて、GPT-4.1は71%、Sonnet 4は62%、Opus 4は69%を記録しました。 その後、2025年夏半ばから2026年初頭にかけて能力が急速に向上し、GPTシリーズとClaudeシリーズの両方が、この100例のサンプルにおいて90%を超える精度を達成した。 この飛躍は、少し遅れてではありますが、Qwen Plusシリーズでも見られ、Qwen3.5 Plusリリースの55%という精度から、わずか2ヶ月後にリリースされたQwen3.6 Plusでは83%へと急上昇しています。
このゼロショットでの優位性は、主にAI生成コンテンツへの慣れによるものなのか、それとも単に知能の差によるものなのか――つまり、より高性能な最先端モデルほど優れた分類器として機能しているのか――と疑問に思う人もいるかもしれません。これを検証するために、コンテキストに(もちろん、トレーニングセットから抽出し、質問ごとにランダムに選択した)フューショット例を挿入することで、精度がどのように変化するかを確認してみましょう。これにより、プロンプトの形式は次のようなフューショットテンプレートにアップグレードされます:
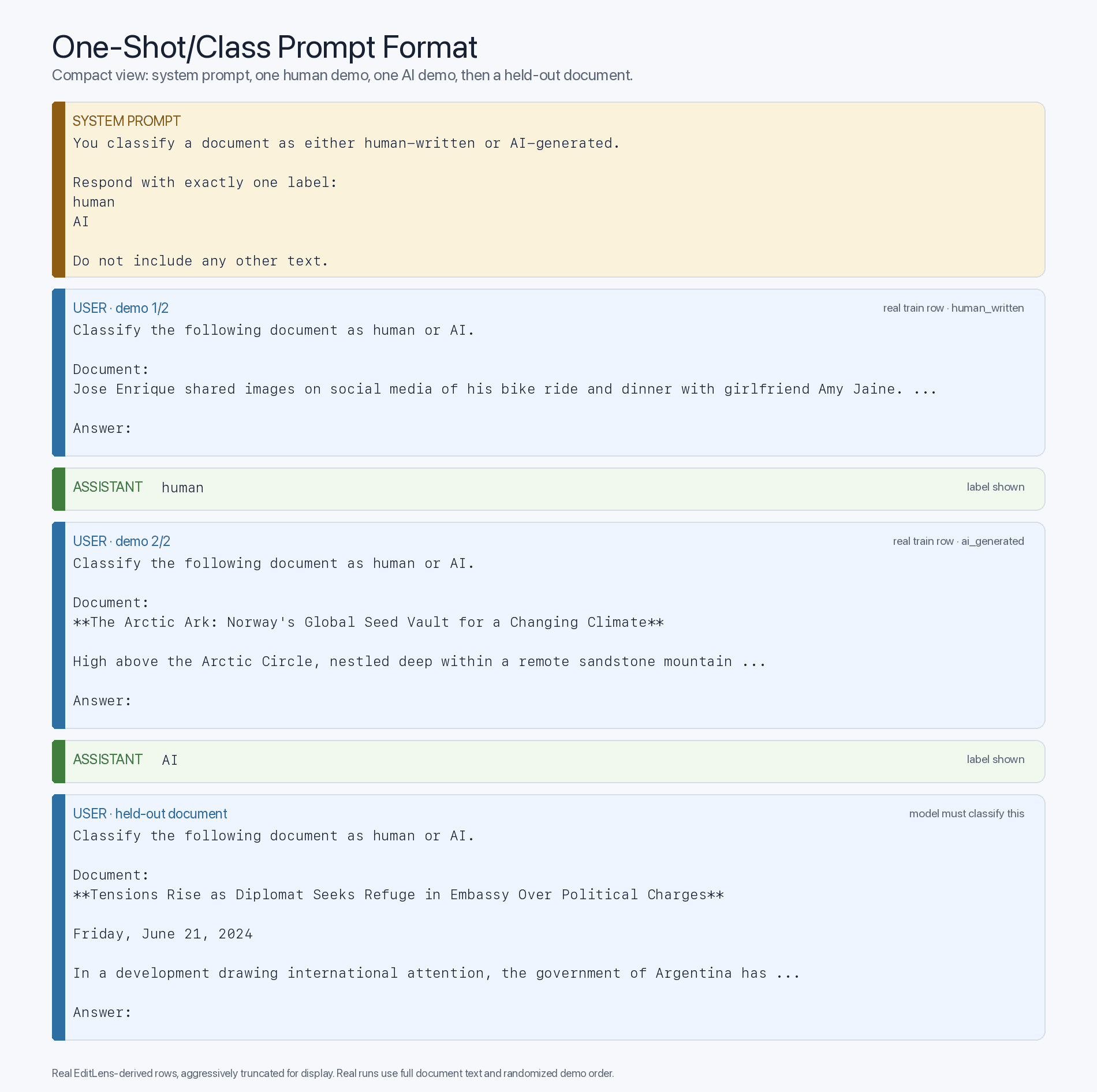
もし、この「少数のショット」というプロンプト形式の下で、古いモデルが適切な入力-ラベルの対応関係に触れることで劇的に性能が向上するのであれば、ボトルネックは事前学習の経験であり、知能そのものではないということになる。そして、まさにそれが我々の観察結果である:
 質問ごとのGPT ICLチャート
質問ごとのGPT ICLチャート
GPT-4のゼロショットでは52%しか正解できなかったのに対し、4ショットでは1 では85%に達する。 GPT-4が文脈に基づいてAI生成テキストと人間が書いたテキストを区別することを学習できることは明らかだ――ただ、その方法に関する生来の事前学習済み知識を持っていないだけである。このことは、ゼロショット性能がモデルの世代が進むにつれてほぼ単調に改善している一方で、ファウショット性能はGPT-5.1以降ほぼ横ばいのままであり、GPT-5.5になって初めて99%まで顕著に上昇していることからも裏付けられている。 この証拠は、LLMがそこそこのゼロショットAI検出器になるために欠けていた要素が、単に適切な事前学習データ(あるいは文脈に沿った「正解」例)であり、その性質や知能に内在する制約ではなかったことを強く示唆している。
コンテキスト内少例学習がICL検出能力に与える影響をさらに詳しく調査するため、より多くのシグナルを抽出できる難易度の高いデータセットが必要でした。何しろ、最先端のモデルが100問の評価で95%の正答率を達成してしまえば、そのデータセットはもはや有用とは言えなくなるからです。この難易度の高いデータセットを構築するため、パングラムデータセットから、Qwen 3.7 Plusを2回(temp=0.7で)騙した例のみを抽出しました。 これにより、AI生成サンプル3,503件と人間作成サンプル763件が得られた。その後、これらを(一様ランダムサンプリングにより)クラスバランス調整し、最終的にAI生成サンプル763件と人間作成サンプル763件からなるハードデータセットを作成した。
この難易度の高いデータセットを用いて、Sonnet 4.6 と GPT-5.5 の両方を、ショット数 0、1、2、4、8 の条件で、推論機能をオフにした場合とオンにした場合(GPT-5.5 は「medium effort」、Sonnet 4.6 は費用対効果を考慮して「simple extended thinking」を設定)で評価しました:
 「ソネット第4.6篇」の図表を整理しました
「ソネット第4.6篇」の図表を整理しました
 GPT-5.5のチャートを整理しました
GPT-5.5のチャートを整理しました
GPT-5.5がSonnet 4.6のゼロショット性能を大幅に上回っていることがわかります。これは、GPT-5.5が2026年4月に、Sonnet 4.6が2026年2月にリリースされたことから予想される結果です。 注目すべきは、ICLを用いることでこの差が大幅に縮小する点です。推論機能をオフにした状態では、GPT-5.5のゼロショット精度は86.8%に対し、Sonnet 4.6は72.9%ですが、8回の試行を行うと、GPT-5.5は96.2%、Sonnet 4.6は93.8%となります。 これは、AI検出の多くが、他のほぼすべてのテキスト分類と同様に、文脈によって習得可能な能力であることをさらに裏付けるものです。
注目すべきは、推論によってGPT-5.5のスコアが数パーセントポイントという大幅な向上を見せた一方で、Sonnet 4.6についてはゼロショット環境でのみ実質的な効果(+2.2%)が見られ、それ以降はほとんど悪影響も好影響も与えていないという点である。 統計的検定でもこの傾向が裏付けられている。ボンフェローニ補正を施した後も、GPT-5.5における推論の効果は0、1、2、8ショットの各条件で統計的に有意なままであるのに対し、Sonnet 4.6ではゼロショットの条件でのみ有意な効果が認められる。
このことは、テスト時の演算処理がAIによる文章分類に役立つ一方で、直感的な判断と比較してそれを効果的に適用できるトレーニングや能力を備えているのは一部のモデルファミリーに限られ、単に文脈に沿った学習用例をさらに提供する場合と比較すると、その効果はそれほど大きくないことを示唆しているようだ。今後の研究では、GPT-5.5を「high」または「xhigh」の推論レベルでテストし、効果が持続するかどうかを確認することが考えられる。
要約すると、現代のLLMはAI生成の文章と人間が書いた文章を正確に見分けることができること、この能力は事前学習段階でAI生成コンテンツに多く触れたことが要因である可能性が高いこと、そしてテスト時の計算リソースからはわずかな恩恵しか得られないものの、文脈に沿った例が増えるほどその性能が大幅に向上すること(GPT-4のような旧式のLLMでさえ、ゼロショットで偶然のレベルにあるベースラインからこれを学習できるほどである)が明らかになった。 これは、ChatGPTにはテキストがAI生成であるかどうかを判別する能力がないという従来の通説に反するものです。しかし、私は依然として、これらを実用的なAI検出器として使用することはしません。ハードセットにおいて、最も性能の高いモデルである ——中程度の推論能力を持つGPT-5.5でさえ、偽陽性率(FPR)が4.59%に達しており、これは日常的な使用においてさえ許容できない数値です(参考までに、最近の研究では、5人の専門家による人間アノテーターの平均偽陽性率は 5.6%でしたが、これらのアノテーターをアンサンブルで組み合わせた場合のFPRは0%でした)。 信頼性の高い検出ツールをお探しなら、私の記事『In Defense of Pangram』で論じた注意点に留意した上で、Pangramをお勧めします。 とはいえ、私はこの能力を依然として非常に興味深いと感じています。過去数年間、LLMはLLMが生成した文章を検出することが全くできないというのが通説であったことを踏まえると、これを記録しておくことは重要だと考えました。むしろ、AI生成文章の検出において、LLMを大まかに「熟練から専門家レベルの人間」と同等とモデル化するのが適切でしょう。それらはかなり正確ですが、誤検知率が1%台にとどまるため、その指摘に基づいて具体的な行動を起こすことはできません。
脚注
-
なお、ここでいう「4-shot」とは、AIの例が4つ、人間の例が4つという意味であり、例が合計4つという意味ではありません。↩

ネイサン・ブレスロー(オンライン上のハンドルネームは N8Programs)は、ジョンズ・ホプキンス大学で応用数学を専攻する学部生である。また、Intelligence Amplification Lab において大規模言語モデル(LLM)のコンテキスト内学習の研究に従事し、ローカル推論フレームワークの開発にも貢献しているほか、珍しいモダリティを用いた言語モデルの事前学習も行っている。本記事で述べられている見解は、あくまで彼個人のものである。





を購読して、最新情報を受け取りましょう
