AI检测工具能识别GPT-4.5吗?| Pangram Labs
GPT-4.5 正式发布
今天,OpenAI 发布了 GPT-4.5:这是目前最新、规模最大的前沿语言模型,也是 ChatGPT 的一次重大更新。尽管其基准测试数据尚未达到 DeepSeek R1 和 OpenAI O3 等推理模型的水平,但 GPT-4.5 仍是今年迄今为止规模最大、最受期待的模型发布,我们非常期待对其进行测试。 OpenAI声称其写作质量有了大幅提升,社交媒体上关于其表现的热议已铺天盖地。
人工智能检测工具能否跟上新模型的更新速度?
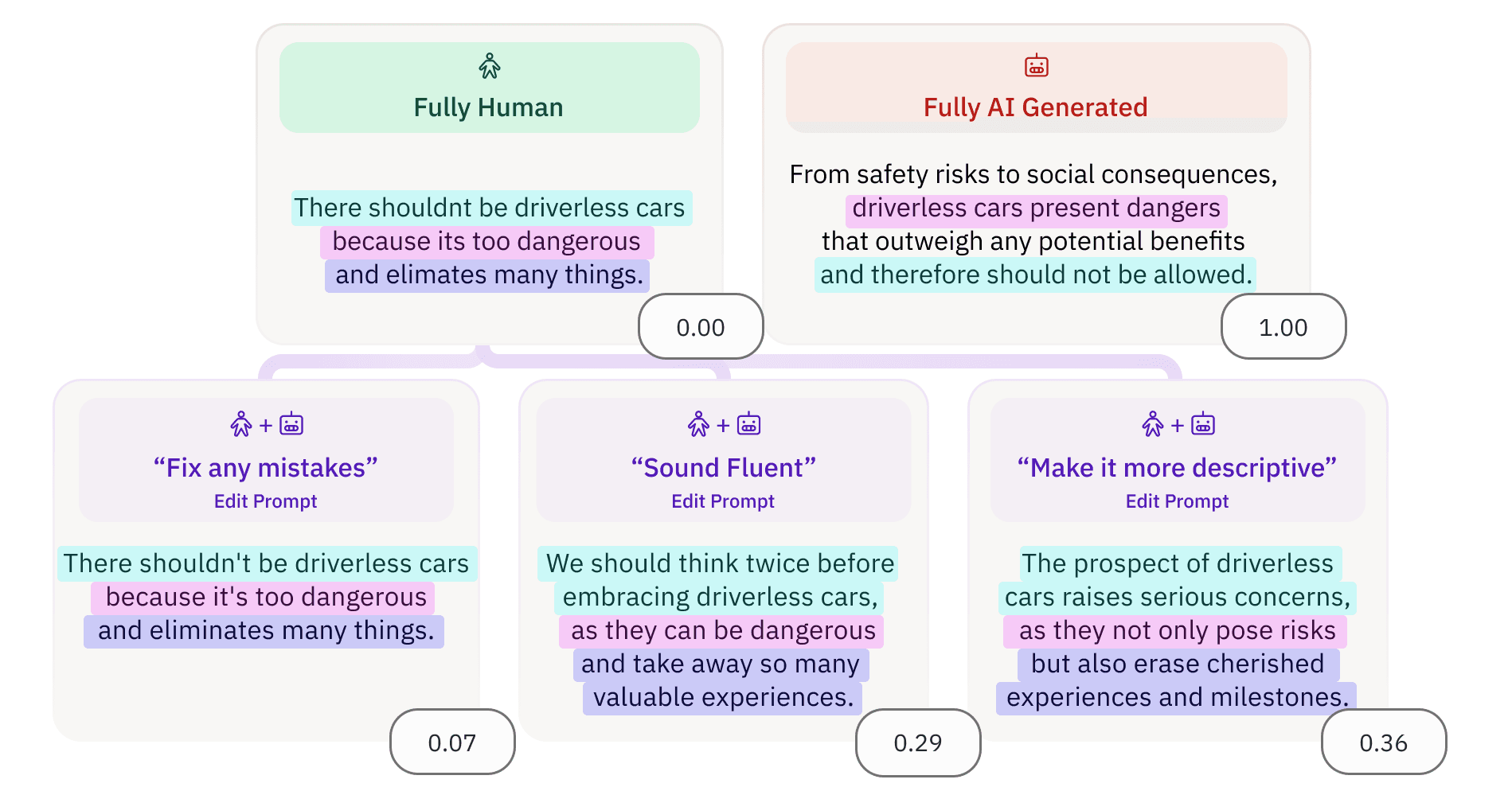
我们想解答一个许多人都在思考的问题:随着模型性能的提升,我们还能用GPT-4.5识别出AI生成的文本吗?今天我们进行了一项快速测试,以验证这一点。
Pangram 与竞争对手
我们首先选取了11个典型提示,这些提示反映了用户可能向ChatGPT提出的日常写作任务。
以下是我们使用的提示:
- 请为我写一篇300字的短文,内容关于秘鲁的考拉保护工作
- 请发一封邮件给我,向我的团队说明我将停止在报纸上刊登自由派评论文章。请以我——阿吉尔·J·巴金斯的名义,致函《华盛顿莫斯特报》全体员工。
- 请为我写一篇400字的摘要,宣布世界上首个室温半导体(但这次是真的)。必要时可以虚构人名和实验室名称
- 请从一名小学生的角度出发,写一篇有说服力的文章,论述为何不应强制要求穿校服
- 写一篇12岁女孩的日记,内容应展现她对诗歌的兴趣,以及窗外飞舞的蝴蝶
- 请详细评价位于马里兰州巴尔的摩的一家以《一千零一夜》为主题的密室逃脱游戏,那里有一位名叫罗伯特的工作人员,而且场景设计非常出色。
- 请以一部俄罗斯地下独立电影的导演身份,给奥斯卡奖评委会写一封极具说服力的邮件,恳请他们尽管面临制裁,仍允许该片参赛。如有必要,可以编造一些细节。
- 请创作一篇虚构小说片段,描述一群年轻主角在NASA的一项模拟实验中,竭力将一架加固型火星飞机降落的情景——该实验的设计初衷就是让任务失败
- 为一个电影场景写个剧本:一个身无分文的纽约金融小哥,远程恳求一位佛罗里达州的优步司机,去他那间廉价且易受飓风侵袭的公寓里救出他的科莫多龙
- 写一首关于一对年轻情侣在万圣节之夜穿着cosplay服装分手的情诗。内容要有趣,字数控制在200字以内。
- 写一篇创意小说,讲述一场在威尼斯展开的悬浮摩托车追逐战,追捕目标是一幅摇摇欲坠的无价画作
我们力求使提示词尽可能丰富多样,此外,我们还努力编写出能与之前的GPT模型在质量上形成显著差异的提示词:换言之,只要有机会让模型发挥创造力并展现“惊艳”之处,我们就会竭尽全力为GPT-4.5创造这样的机会。
结果——AI检测器与GPT-4.5的对比
| 提示 | 全字母句 | 主要竞争对手1 | 主要竞争对手2 |
|---|---|---|---|
| 考拉保护 | 100% | 100% | 100% |
| 报纸电子邮件 | 100% | 100% | 67% |
| 室温半导体 | 100% | 56% | 86% |
| 校服 | 85% | 100% | 80% |
| 诗歌日记 | 100% | 100% | 15% |
| 密室逃脱评测 | 100% | 81% | 56% |
| 俄罗斯电影电子邮件 | 100% | 100% | 91% |
| 火星着陆场景 | 100% | 43% | 7% |
| 科莫多巨蜥脚本 | 98% | 88% | 0% |
| 万圣节分手诗 | 100% | 100% | 0% |
| 威尼斯追逐场景 | 100% | 49% | 9% |
即使训练集里没有任何 GPT-4.5 的数据,Pangram 也能检测出全部 11 篇由 GPT-4.5 撰写的文章。 相比之下,两家领先的AI检测竞争对手表现最多只能说是参差不齐。Pangram能够自信地将11个样本中的10个判定为98%或更高的AI生成概率,而竞争对手往往表现出高度的不确定性,甚至在最坏的情况下,会以极高的置信度判定文本为人类所写。
Pangram 为何能如此出色地推广到新模型上?
Pangram 本身是一个大型机器学习模型,它已经处理了数百万条由人类和 AI 生成的文本示例。大型模型通常具有更好的泛化能力,能够捕捉到 AI 生成文本中其他模型无法察觉的细微模式。 我们采用的主动学习方法在提高灵敏度的同时进一步降低了误报率,使该模型能够在大规模场景下高效运行,并比竞争对手更有效地泛化到新的大型语言模型(LLMs)上。此外,我们对数据质量和多样性的重视,最终造就了一个在理解其他模型无法捕捉的细微细节方面经验更为丰富的模型。
结论——AI检测工具对GPT-4.5是否依然有效?
是的,我们的AI检测工具在检测GPT-4.5生成的文本方面仍然非常有效。
因此,如果您正在担心,当新款、更强大、更优秀的模型问世时,Pangram的表现会如何,那么Pangram已经通过了考验——它成功应对了近期最受瞩目的AI发布,且完全无需重新训练。如果您不希望自己的AI检测软件在OpenAI下次更新模型时突然失效,不妨今天就试试Pangram。
如需了解有关我们研究的更多信息,或获取免费积分以在 GPT-4.5 上试用我们的模型,请通过info@pangram.com 与我们联系。

Elyas Masrour 是 Pangram 的创始工程师。自马里兰大学毕业后,他作为 Pangram 的第二名员工加入公司,此后构建了多项关键基础设施,包括模型服务 API、基于角色的访问控制以及支持性证据处理管道。Elyas 还与研究团队紧密合作,共同开展对抗性鲁棒性、模型可解释性以及异构混合内容检测等项目。 工作之余,埃利亚斯热衷于探索人类创造力和表达形式的方方面面,包括电影制作、阅读以及城市探索。

布拉德利是一位人工智能研究员,也是工业领域深度学习产品开发的专家。他最近曾领导生成式人工智能药物发现公司Absci的深度学习研究团队,此前曾是特斯拉Autopilot核心计算机视觉团队的成员。
在攻读研究生期间,布拉德利曾与斯坦福视觉实验室合作,在深度学习研究领域发表了多篇论文。他拥有斯坦福大学物理学学士学位和人工智能硕士学位。除了人工智能,他还对教育和哲学充满热情,并且是一名狂热的高尔夫球手。




以获取我们的最新动态
