宣布发布 Pangram 3.2
更新:Pangram 3.3 现已发布,敬请查阅Pangram 3.3 的新功能。
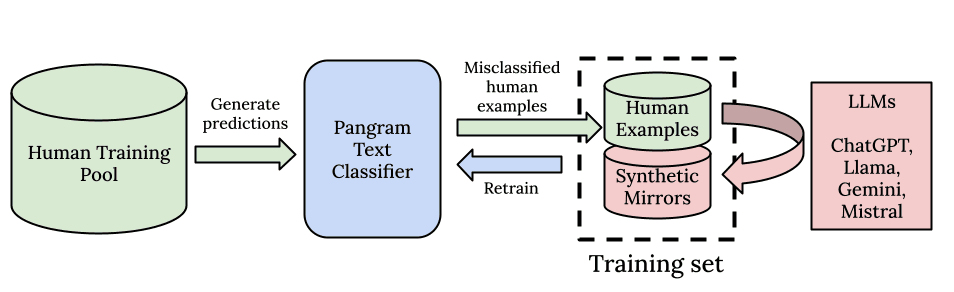
Pangram 非常激动地发布了一款新的 AI 检测模型——Pangram 3.2。与之前的 Pangram 3.1 和 Pangram 3.0 一样,该模型基于我们在ICLR 2026 论文中描述的 EditLens 架构。 用户将看到检测器在真阳性率(即召回率)方面实现了渐进但显著的提升,同时仍保持业界最低的误报率,确保因误判而产生的AI使用指控依然极为罕见。
模特卡
借鉴大型语言模型(LLM)发布的最佳实践,我们决定在发布检测器更新时同步发布“模型卡片”——这实质上是AI模型的“营养标签”。我们的模型卡片详细说明了训练架构和框架、训练数据集的具体信息、相关评估结果,以及可能影响检测器行为的变更。 此外,我们还详细说明了模型的输入和输出规格、支持的语言,以及在哪些条件下 Pangram 表现优异,以及其能力受限的场景。
您将体验到什么
您可能会注意到,Pangram 3.2的灵敏度比Pangram 3.1更高。换句话说,它能检测出更多由 AI 生成的文本。这得益于以下方面的改进:Humanizer 检测功能的优化、对 Claude 4.6 的检测能力提升、对较短 AI 生成文本检测灵敏度的增强、训练数据集的扩充,以及 EditLens 架构中更优化的超参数设置。
有哪些改进
人性化检测与对抗性提示
Pangram 3.2 的最大改进在于其能够检测由 AI 生成的拟人化文本。 在我们的内部“拟人化生成器”评估集上,相较于 Pangram 3.1,我们将其检测率提升了 4 倍。此外,在针对“对抗性提示词”的内部评估中,我们还观察到约 3 倍的性能提升。所谓“对抗性提示词”,是指由语言模型生成的文本,这些模型被指令要求故意添加错误,并采用一种能够规避 AI 检测的写作风格。
这一点在教育领域尤为重要,因为学生们越来越多地使用“人性化”工具,或尝试以某种方式引导语言模型,以避免生成的文本给人一种“过于像AI生成的”感觉。
识别由人工智能生成的社交媒体短文
鉴于我们的X平台机器人广受欢迎——用户常利用它来检测推文中是否存在AI生成的内容——我们近期一直致力于提升对网络上短篇(推文长度)内容的检测能力。此外,我们将最低字数要求从75字下调至50字,因为我们对识别50至75字范围内AI生成帖子的能力更加有信心。
在与 Pangram 3.1 相同的假阳性率下,我们在 Pangram 3.2 中将短篇社交媒体帖子的假阴性率降低了 17%。
Claude 4.6 改进
许多用户反映,在检测Claude Opus 4.6时出现了误报。为此,我们已重新生成数据集,其中纳入了Claude Opus 4.6的相关数据。经过在内部挑战数据集(尤其是高难度样本)上的评估以及红队测试,我们现在有信心认为,Pangram能够像检测其他前沿大语言模型一样,有效检测Claude Opus 4.6。
接下来会发生什么
由人工智能生成的数学、代码和科学
目前,AI生成的代码和数学内容尚未能被高准确率地检测出来。鉴于客户对此需求强烈,我们目前正重点关注这些应用场景。虽然数学和代码更具公式化特征,因此比AI生成的文本更难检测,但我们的一些早期实验已显示出令人鼓舞的结果。
对“Humanizers”的持续迭代
拟人化工具市场正在不断发展,近几个月来,市场上出现了种类更加丰富的拟人化工具。我们正在开发更先进的拟人化工具检测技术,希望不久后能向公众发布。
未来
Pangram 致力于始终站在人工智能检测技术的前沿。随着大型语言模型(LLM)能力的不断提升,我们也在不断进化。
我们正在招聘!欢迎访问我们的招聘页面,加入我们,共同打造全球顶尖的AI检测工具。

凯瑟琳·泰(Katherine Thai)是人工智能检测初创公司Pangram Labs的创始人工智能研究科学家。她于2025年12月在马萨诸塞大学阿默斯特分校,在莫希特·伊耶(Mohit Iyyer)的指导下获得了计算机科学博士学位,其研究主要致力于评估大型语言模型(LLMs)在文学分析相关任务中的表现。